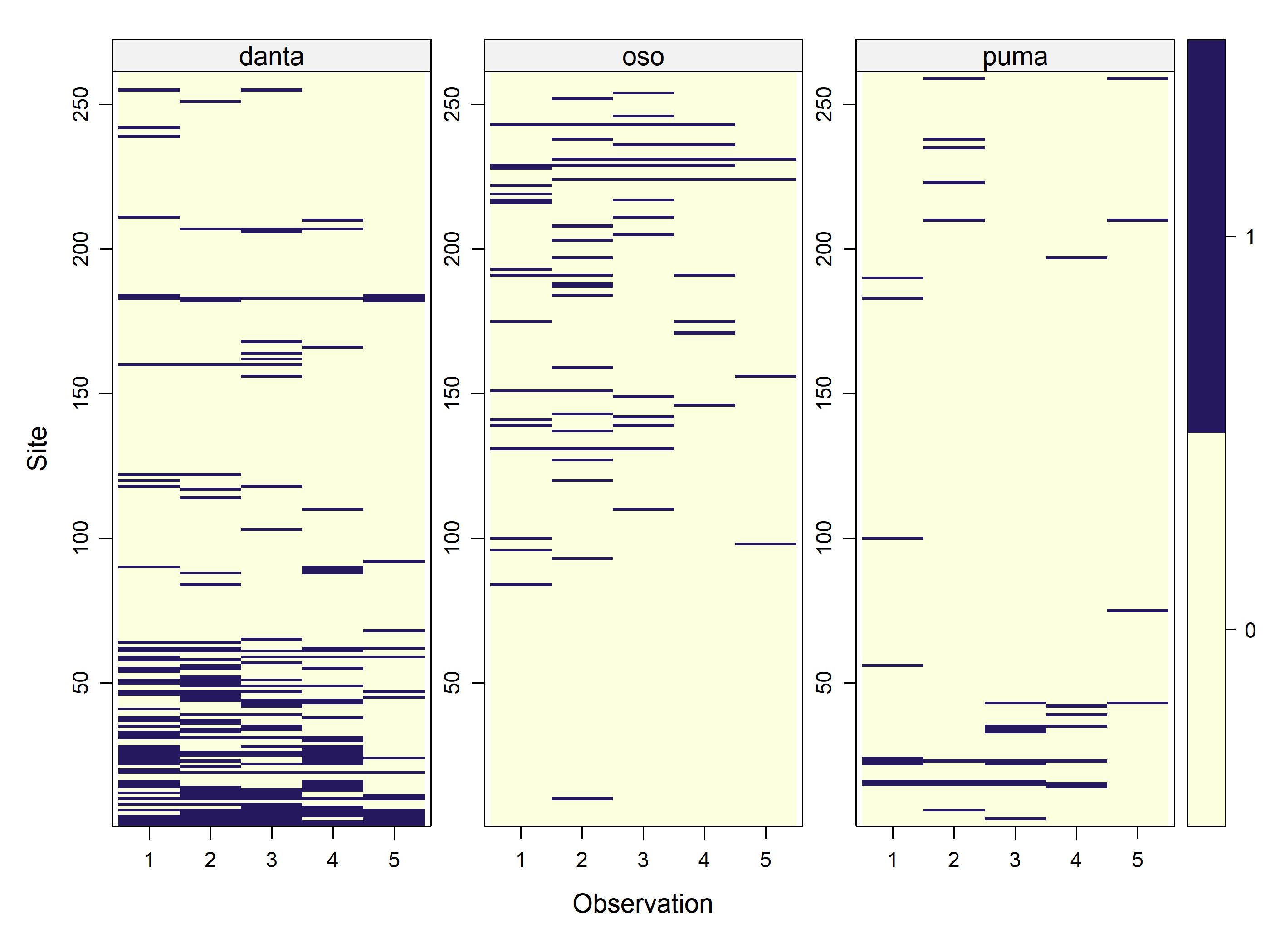
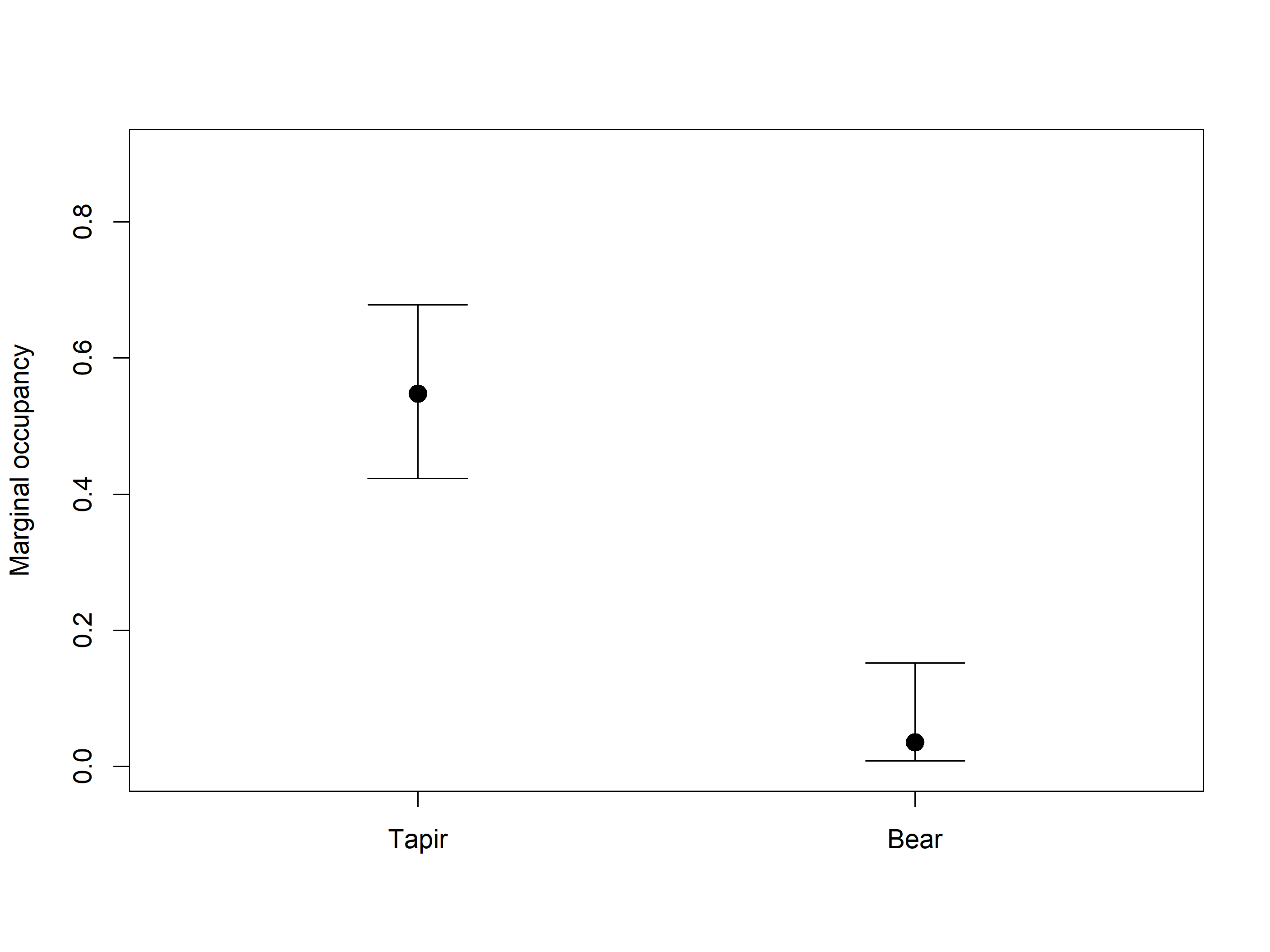
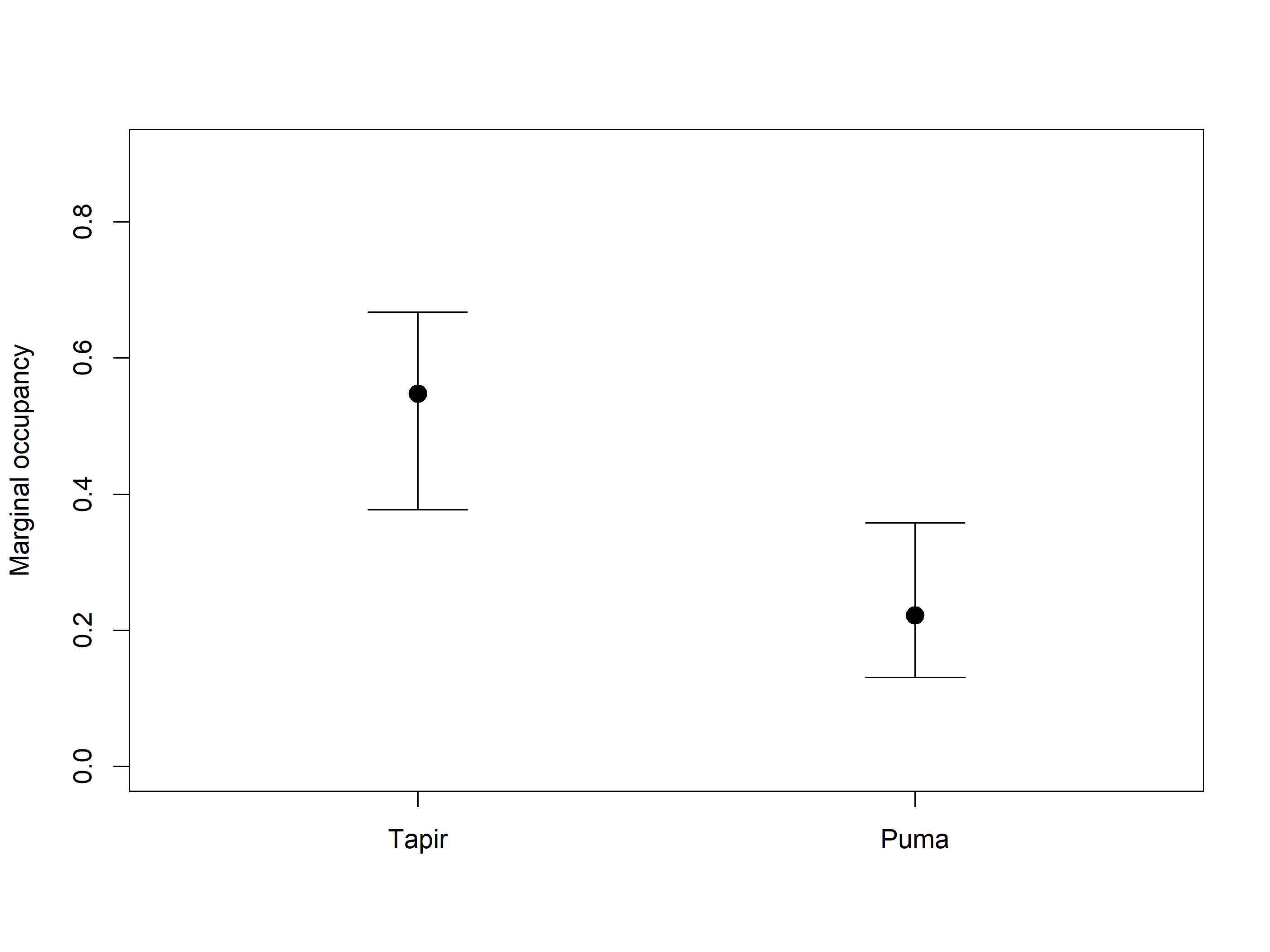
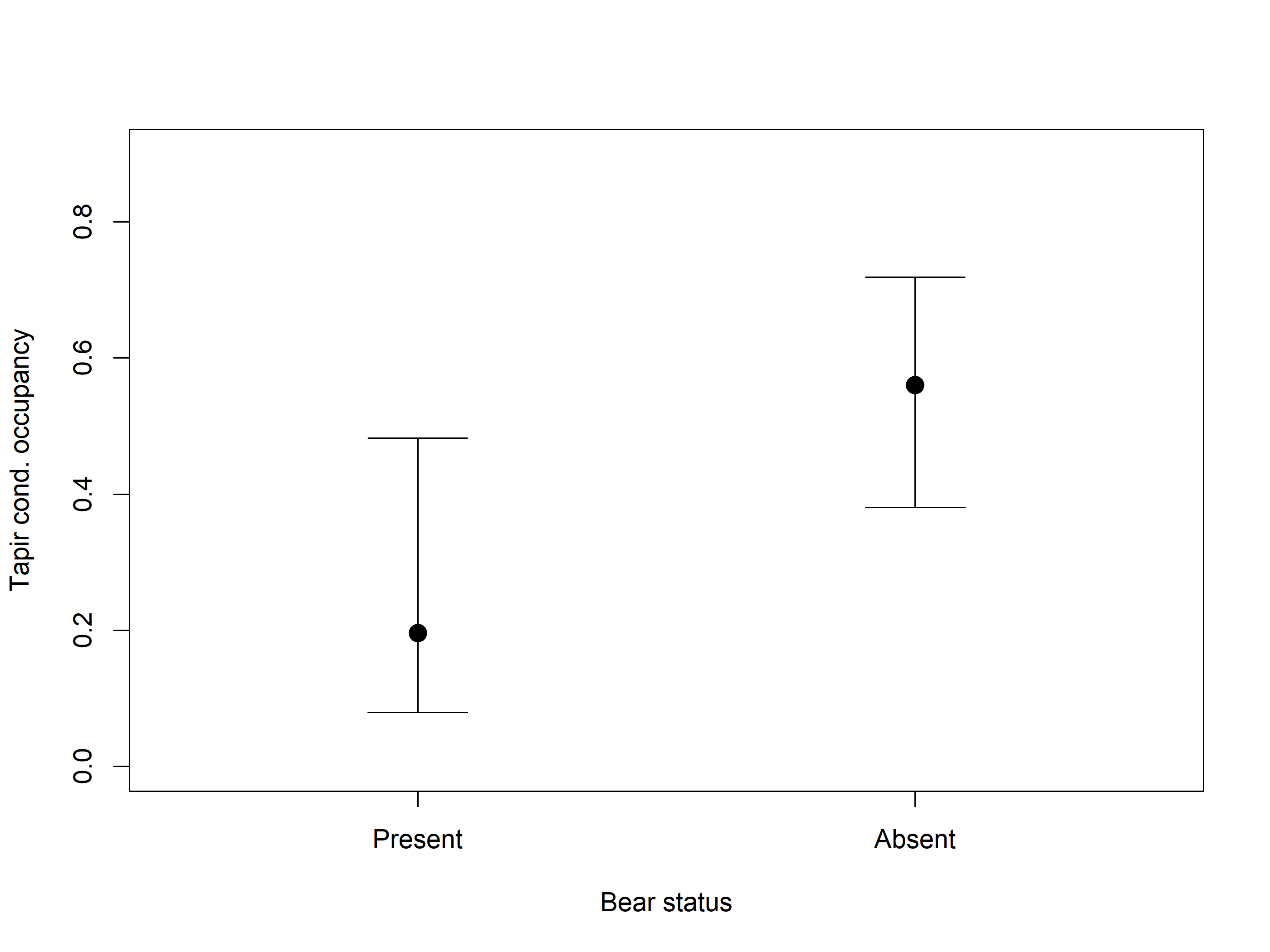
Allaire, JJ, and Christophe Dervieux. 2024.
quarto: R Interface to “Quarto” Markdown Publishing System.
https://CRAN.R-project.org/package=quarto.
Allaire, JJ, Yihui Xie, Christophe Dervieux, et al. 2024.
rmarkdown: Dynamic Documents for r.
https://github.com/rstudio/rmarkdown.
Appelhans, Tim, Florian Detsch, Christoph Reudenbach, and Stefan Woellauer. 2023.
mapview: Interactive Viewing of Spatial Data in r.
https://CRAN.R-project.org/package=mapview.
Fiske, Ian, and Richard Chandler. 2011.
“unmarked: An R Package for Fitting Hierarchical Models of Wildlife Occurrence and Abundance.” Journal of Statistical Software 43 (10): 1–23.
https://www.jstatsoft.org/v43/i10/.
Hester, Jim, and Jennifer Bryan. 2024.
glue: Interpreted String Literals.
https://CRAN.R-project.org/package=glue.
Hijmans, Robert J. 2024.
terra: Spatial Data Analysis.
https://CRAN.R-project.org/package=terra.
Hollister, Jeffrey, Tarak Shah, Jakub Nowosad, Alec L. Robitaille, Marcus W. Beck, and Mike Johnson. 2023.
elevatr: Access Elevation Data from Various APIs.
https://doi.org/10.5281/zenodo.8335450.
Kellner, Kenneth F., Nicholas L. Fowler, Tyler R. Petroelje, Todd M. Kautz, Dean E. Beyer, and Jerrold L. Belant. 2021.
“ubms: An R Package for Fitting Hierarchical Occupancy and n-Mixture Abundance Models in a Bayesian Framework.” Methods in Ecology and Evolution 13: 577–84.
https://doi.org/10.1111/2041-210X.13777.
Kellner, Kenneth F., Adam D. Smith, J. Andrew Royle, Marc Kery, Jerrold L. Belant, and Richard B. Chandler. 2023.
“The unmarked R Package: Twelve Years of Advances in Occurrence and Abundance Modelling in Ecology.” Methods in Ecology and Evolution 14 (6): 1408–15.
https://www.jstatsoft.org/v43/i10/.
Müller, Kirill, and Lorenz Walthert. 2024.
styler: Non-Invasive Pretty Printing of r Code.
https://CRAN.R-project.org/package=styler.
Niedballa, Jürgen, Rahel Sollmann, Alexandre Courtiol, and Andreas Wilting. 2016.
“camtrapR: An r Package for Efficient Camera Trap Data Management.” Methods in Ecology and Evolution 7 (12): 1457–62.
https://doi.org/10.1111/2041-210X.12600.
Pebesma, Edzer. 2018.
“Simple Features for R: Standardized Support for Spatial Vector Data.” The R Journal 10 (1): 439–46.
https://doi.org/10.32614/RJ-2018-009.
Pebesma, Edzer, and Roger Bivand. 2023a.
Spatial Data Science: With applications in R.
Chapman and Hall/CRC.
https://doi.org/10.1201/9780429459016.
Pebesma, Edzer, and Roger Bivand. 2023b.
Spatial Data Science: With applications in R. Chapman; Hall/CRC.
https://doi.org/10.1201/9780429459016.
Pedersen, Thomas Lin. 2024a.
ggforce: Accelerating “ggplot2”.
https://CRAN.R-project.org/package=ggforce.
Pedersen, Thomas Lin. 2024b.
patchwork: The Composer of Plots.
https://CRAN.R-project.org/package=patchwork.
R Core Team. 2023.
R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing.
https://www.R-project.org/.
Wickham, Hadley, Mara Averick, Jennifer Bryan, et al. 2019.
“Welcome to the tidyverse.” Journal of Open Source Software 4 (43): 1686.
https://doi.org/10.21105/joss.01686.
Xie, Yihui. 2014. “knitr: A Comprehensive Tool for Reproducible Research in R.” In Implementing Reproducible Computational Research, edited by Victoria Stodden, Friedrich Leisch, and Roger D. Peng. Chapman; Hall/CRC.
Xie, Yihui. 2015.
Dynamic Documents with R and Knitr. 2nd ed. Chapman; Hall/CRC.
https://yihui.org/knitr/.
Xie, Yihui. 2024.
knitr: A General-Purpose Package for Dynamic Report Generation in r.
https://yihui.org/knitr/.
Xie, Yihui, J. J. Allaire, and Garrett Grolemund. 2018.
R Markdown: The Definitive Guide. Chapman; Hall/CRC.
https://bookdown.org/yihui/rmarkdown.
Xie, Yihui, Joe Cheng, and Xianying Tan. 2024.
DT: A Wrapper of the JavaScript Library “DataTables”.
https://CRAN.R-project.org/package=DT.
Xie, Yihui, Christophe Dervieux, and Emily Riederer. 2020.
R Markdown Cookbook. Chapman; Hall/CRC.
https://bookdown.org/yihui/rmarkdown-cookbook.