Suppose you have a dataset of repeated detections/non detections or counts that are collected over several years, but do not want to fit a dynamic model.
Multi-season (or dynamic) models are commonly used to estimate colonization and/or extinction probabilities, and to test hypotheses on these parameters (using covariates on the parameters gamma and epsilon). This approach needs good amounts of data (many sites, and specially many seasons or years). If you don’t need to estimate dynamic parameters (Colonization or extinction, gamma and epsilon) but you’d like to test for temporal variation in occupancy (Psi) between two or three years taking in to account detection probability (p) you could apply a single-season model with random effects (being random effects the camera trap, sampling unit, or site), by stacking years (i.e., your sampling units would be combination camera-years).
Using random effects with ubms
One of the advantages of the package ubms is that it is possible to include random effects easily in your models, using the same syntax as lme4 (Bates et al. 2015). For example, if you have a group or site covariate, you can fit a model with random intercepts by group-site by including + (1|site) in your parameter formula. Random slopes, or a combination of random slopes and intercepts, are also possible.
To illustrate the use of random effects using the package ubms, in this post, we fit a model using a “stacked” model approach. Additionally in ubms you can instead include, for example, random site intercepts to account for possible pseudoreplication, or handle the temporal autocorrelation structure of o two-three year dataset.
Recently (February 2025) version 1.5.0 of unmarked also incorporated random effects and community models.
The “stacked” model
An alternative approach to try a dynamic model, is to fit multiple years of data into a single-season model, using the “stacked” approach. Essentially, you treat unique site-year combinations as sites and can make occupancy comparisons between years.
There are several potential reasons for this:
Take in to account that dynamic models and Dail-Madsen type models are particularly data hungry.
You are not interested in the transition probabilities (colonization or extinction rates).
You have very few years or seasons (less than five) in your sampling design, and the occupancy did not changed substantially in those few years.
This is specially useful if you only have 2 years of data, so there is no great gain in fitting a dynamic occupancy model with the four parameters parameters \(\Psi\), \(p\), \(\gamma\), and \(\epsilon\), especially if you have a low number of detections and few years or seasond. So the best approach is combining (stacking) the two-treee years, and running a single season occupancy model, with just two parameters (\(\Psi\) and \(p\) instead of four parameters), with year as an explanatory variable and the site as random effect as using lme4 notation as:
model <- occu (~ effort ~ elevation + year + (1 | site), data = newOccu)
Notice we used the function st_jitter() because the points are on top of the previous year.
Extract site covariates
Using the coordinates of the sf object (datos_sf) we put the cameras on top of the covaraies and with the function terra::extract() we get the covariate value.
In this case we used as covariates:
Cattle distribution as number of cows per 10 square kilometer (Gilbert et al. 2018).
#load rastersper_tree_cov<-rast("C:/CodigoR/WCS-CameraTrap/raster/latlon/Veg_Cont_Fields_Yearly_250m_v61/Perc_TreeCov/MOD44B_Perc_TreeCov_2021_065.tif")road_den<-rast("C:/CodigoR/WCS-CameraTrap/raster/latlon/RoadDensity/grip4_total_dens_m_km2.asc")# elev <- rast("D:/CORREGIDAS/elevation_z7.tif")landcov<-rast("C:/CodigoR/WCS-CameraTrap/raster/latlon/LandCover_Type_Yearly_500m_v61/LC1/MCD12Q1_LC1_2021_001.tif")cattle<-rast("C:/CodigoR/WCS-CameraTrap/raster/latlon/Global cattle distribution/5_Ct_2010_Da.tif")#river <- st_read("F:/WCS-CameraTrap/shp/DensidadRios/MCD12Q1_LC1_2001_001_RECLASS_MASK_GRID_3600m_DensDrenSouthAmer.shp")# get elevation map# elevation_detailed <- rast(get_elev_raster(sites, z = 10, clip="bbox", neg_to_na=TRUE))# elevation_detailed <- get_elev_point (datos_sf, src="aws", overwrite=TRUE)# extract covs using points and add to sites# covs <- cbind(sites, terra::extract(SiteCovsRast, sites))per_tre<-terra::extract(per_tree_cov, datos_sf)roads<-terra::extract(road_den, datos_sf)# eleva <- terra::extract(elevation_detailed, sites)land_cov<-terra::extract(landcov, datos_sf)cattle_den<-terra::extract(cattle, datos_sf)#### drop geometry sites<-datos_sf%>%mutate(lat =st_coordinates(.)[,1], lon =st_coordinates(.)[,2])%>%st_drop_geometry()|>as.data.frame()# remove decimals convert to factorsites$land_cover<-factor(land_cov$MCD12Q1_LC1_2021_001)# sites$elevation <- eleva$file3be898018c3sites$per_tree_cov<-per_tre$MOD44B_Perc_TreeCov_2021_065# fix 200 isueind<-which(sites$per_tree_cov==200)sites$per_tree_cov[ind]<-0# sites$elevation <- elevation_detailed$elevationsites$roads<-roads$grip4_total_dens_m_km2sites$cattle<-cattle_den[,2]write.csv(sites, "C:/CodigoR/CameraTrapCesar/data/katios/stacked/site_covs.csv")
Select by years and convert to stacked format
To get the detection history we use the function detectionHistory of the camtrapR package.
TipTake in to account, at the end we need to stack the data in this format:
obs1
obs2
obs3
site
year
0
0
0
1
1
0
0
0
2
1
1
NA
NA
3
1
0
0
0
4
1
0
0
0
1
2
1
0
1
2
2
0
1
NA
3
2
So we need to go by years and then stack de two tables.
First year 2021
Here we use the function detectionHistory() from the package camtrapR to generate species detection histories that can be used later in occupancy analyses, with package unmarked and ubms. detectionHistory() generates detection histories in different formats, with adjustable occasion length and occasion start time and effort covariates. Notice we first need to get the camera operation dates using the function cameraOperation().
Code
# filter first year and make uniquesCToperation_2021<-cam_deploy_image|>#multi-season datafilter(samp_year==2021)|>group_by(deployment_id)|>mutate(minStart=min(start_date), maxEnd=max(end_date))|>distinct(longitude, latitude, minStart, maxEnd, samp_year)|>ungroup()|>as.data.frame()# Fix NA camera 16CToperation_2021[16,]<-c("CT-K1-31-124", -77.2787, 7.73855, "2021-10-10", "2021-12-31", 2021)# make numeric sampling yearCToperation_2021$samp_year<-as.numeric(CToperation_2021$samp_year)# camera operation matrix for _2021# multi-season data. Season1camop_2021<-cameraOperation(CTtable=CToperation_2021, # Tabla de operación stationCol="deployment_id", # Columna que define la estación setupCol="minStart", #Columna fecha de colocación retrievalCol="maxEnd", #Columna fecha de retiro sessionCol ="samp_year", # multi-season column#hasProblems= T, # Hubo fallos de cámaras dateFormat="%Y-%m-%d")#, #, # Formato de las fechas#cameraCol="CT")#sessionCol= "samp_year")# Generar las historias de detección ---------------------------------------## remove plroblem species# ind <- which(datos_PCF$Species=="Marmosa sp.")# datos_PCF <- datos_PCF[-ind,]# filter y1datay_2021<-cam_deploy_image|>filter(samp_year==2021)# |> # filter(samp_year==2022) DetHist_list_2021<-lapply(unique(datay_2021$scientificName), FUN =function(x){detectionHistory( recordTable =datay_2021, # Tabla de registros camOp =camop_2021, # Matriz de operación de cámaras stationCol ="deployment_id", speciesCol ="scientificName", recordDateTimeCol ="timestamp", recordDateTimeFormat ="%Y-%m-%d %H:%M:%S", species =x, # la función reemplaza x por cada una de las especies occasionLength =15, # Colapso de las historias a días day1 ="station", #inicie en la fecha de cada survey datesAsOccasionNames =FALSE, includeEffort =TRUE, scaleEffort =FALSE, unmarkedMultFrameInput=TRUE, timeZone ="America/Bogota")})# namesnames(DetHist_list_2021)<-unique(datay_2021$scientificName)# Finalmente creamos una lista nueva donde estén solo las historias de detecciónylist_2021<-lapply(DetHist_list_2021, FUN =function(x)x$detection_history)# y el esfuerzoeffortlist_2021<-lapply(DetHist_list_2021, FUN =function(x)x$effort)### Danta, Jaguarwhich(names(ylist_2021)=="Tapirus bairdii")#> integer(0)which(names(ylist_2021)=="Panthera onca")#> [1] 5
Next, the year 2022
Code
# filter firs year and make uniquesCToperation_2022<-cam_deploy_image|>#multi-season datafilter(samp_year==2022)|>group_by(deployment_id)|>mutate(minStart=min(start_date), maxEnd=max(end_date))|>distinct(longitude, latitude, minStart, maxEnd, samp_year)|>ungroup()|>as.data.frame()# Fix NA camera 16# CToperation_2022[16,] <- c("CT-K1-31-124", -77.2787, 7.73855, # "2022-10-10", "2022-12-31", 2022)# make numeric sampling yearCToperation_2022$samp_year<-as.numeric(CToperation_2022$samp_year)# camera operation matrix for _2022# multi-season data. Season1camop_2022<-cameraOperation(CTtable=CToperation_2022, # Tabla de operación stationCol="deployment_id", # Columna que define la estación setupCol="minStart", #Columna fecha de colocación retrievalCol="maxEnd", #Columna fecha de retiro sessionCol ="samp_year", # multi-season column#hasProblems= T, # Hubo fallos de cámaras dateFormat="%Y-%m-%d")#, #, # Formato de las fechas#cameraCol="CT")#sessionCol= "samp_year")# Generar las historias de detección ---------------------------------------## remove plroblem species# ind <- which(datos_PCF$Species=="Marmosa sp.")# datos_PCF <- datos_PCF[-ind,]# filter y1datay_2022<-cam_deploy_image|>filter(samp_year==2022)# |> # filter(samp_year==2022) DetHist_list_2022<-lapply(unique(datay_2022$scientificName), FUN =function(x){detectionHistory( recordTable =datay_2022, # Tabla de registros camOp =camop_2022, # Matriz de operación de cámaras stationCol ="deployment_id", speciesCol ="scientificName", recordDateTimeCol ="timestamp", recordDateTimeFormat ="%Y-%m-%d %H:%M:%S", species =x, # la función reemplaza x por cada una de las especies occasionLength =25, # Colapso de las historias a días day1 ="station", #inicie en la fecha de cada survey datesAsOccasionNames =FALSE, includeEffort =TRUE, scaleEffort =FALSE, unmarkedMultFrameInput=TRUE, timeZone ="America/Bogota")})# namesnames(DetHist_list_2022)<-unique(datay_2022$scientificName)# Finalmente creamos una lista nueva donde estén solo las historias de detecciónylist_2022<-lapply(DetHist_list_2022, FUN =function(x)x$detection_history)effortlist_2022<-lapply(DetHist_list_2022, FUN =function(x)x$effort)### Danta, Jaguar### Danta, Jaguarwhich(names(ylist_2022)=="Tapirus bairdii")#> [1] 21which(names(ylist_2022)=="Panthera onca")#> [1] 19
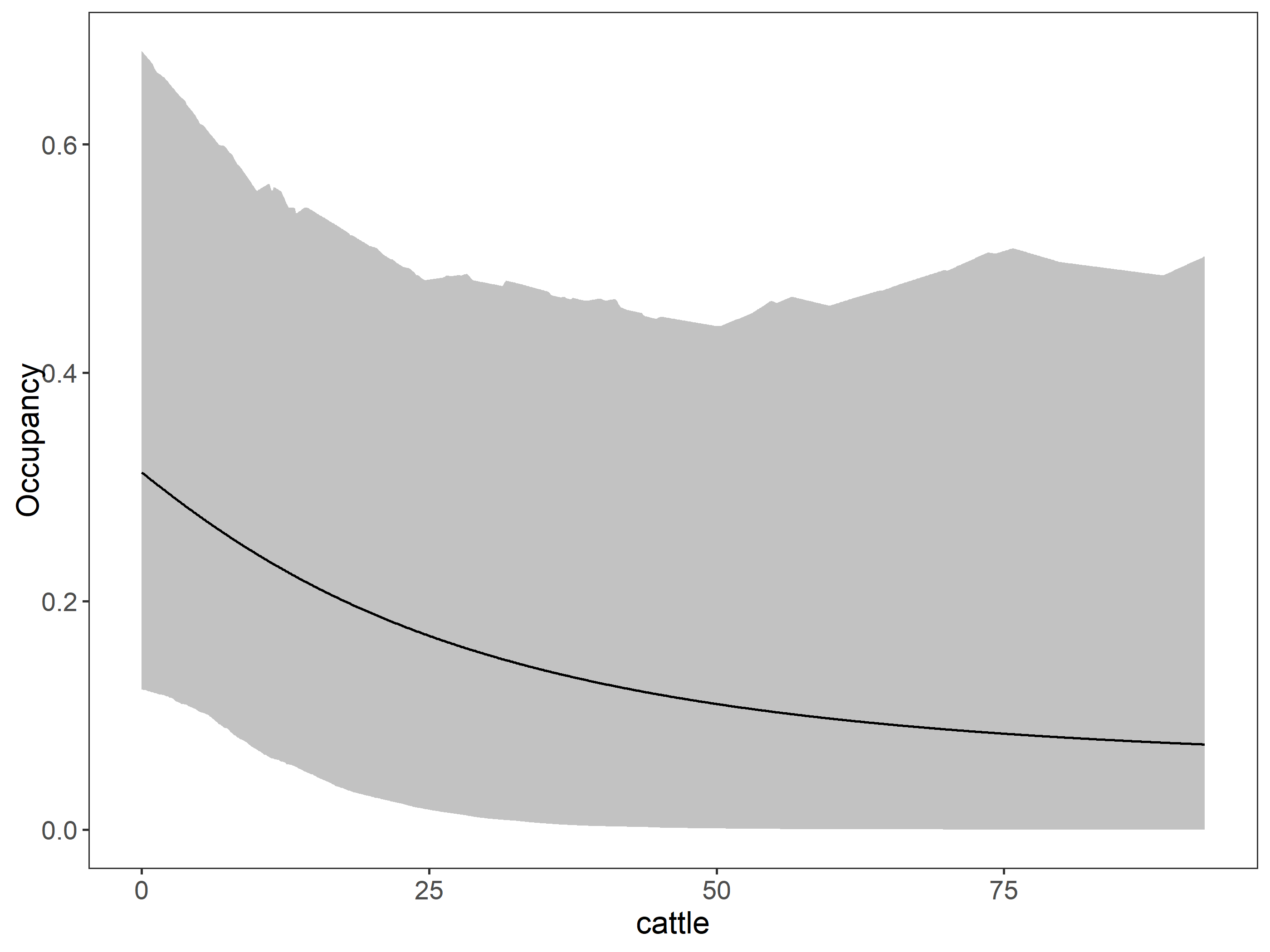
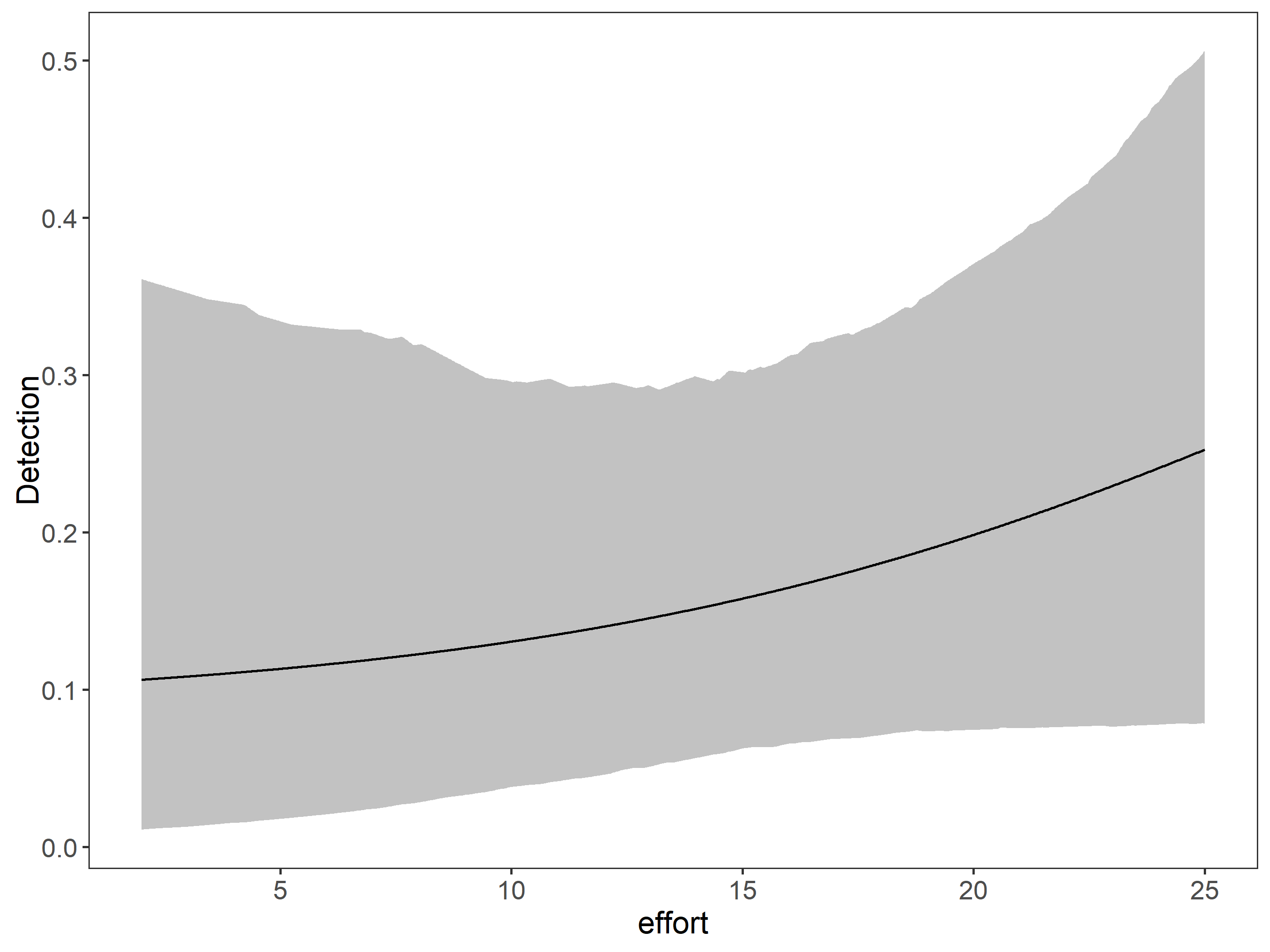
Lets use the ubms package to make a stacked occupancy model pooling 2021 and 2022 data together and use the percent tree cover, the road density and the cattle density as covariates for the occupancy and the effort as the number of sampling days as covariate for detection.
Notice we collapsed the events to 15 days in the 2021 sampling season, and to 25 days in the 2022 sampling season, to end with 6 repeated observations in de matrix. In the matrix o1 to o6 are observations and e1 to e6 are sampling effort (observation-detection covariates). Land_cover, per_tree_cov and roads are site covariates (occupancy covariate).
Create an unmarked frame
With our stacked dataset constructed, we build the unmarkedFrameOccu() object, organizing detection, non-detection data along with the covariates.
Code
# fix NA spread# yj <- rbind(ylist[[62]][1:30,1:8], # 62 is Jaguar# ylist[[62]][31:50,12:19])# ej <- rbind(effortlist[[4]][1:30,1:8],# effortlist[[4]][31:50,12:19])jaguar_covs<-jaguar[,c(8,9,16:19)]jaguar_covs$year<-as.factor(jaguar_covs$year)umf<-unmarkedFrameOccu(y=jaguar[,2:7], siteCovs=jaguar_covs, obsCovs=list(effort=jaguar[10:15]))plot(umf)
Fit models
Fit the Stacked Model
We’ll now we fit a model with fixed effects of percent tree cover road density and cattle density (per_tree_cov, roads and cattle) on occupancy, and a effort as the detection covariate. In addition, we will include random intercepts by site, since in stacking the data we have pseudoreplication by site. To remember, random effects are specified using the same notation used in with the lme4 package. For example, a random intercept for each level of the covariate site is specified with the formula component (1|site). Take in to account, Including random effects in a model in ubms usually significantly increases the run time, but at the end is worth the waiting time.
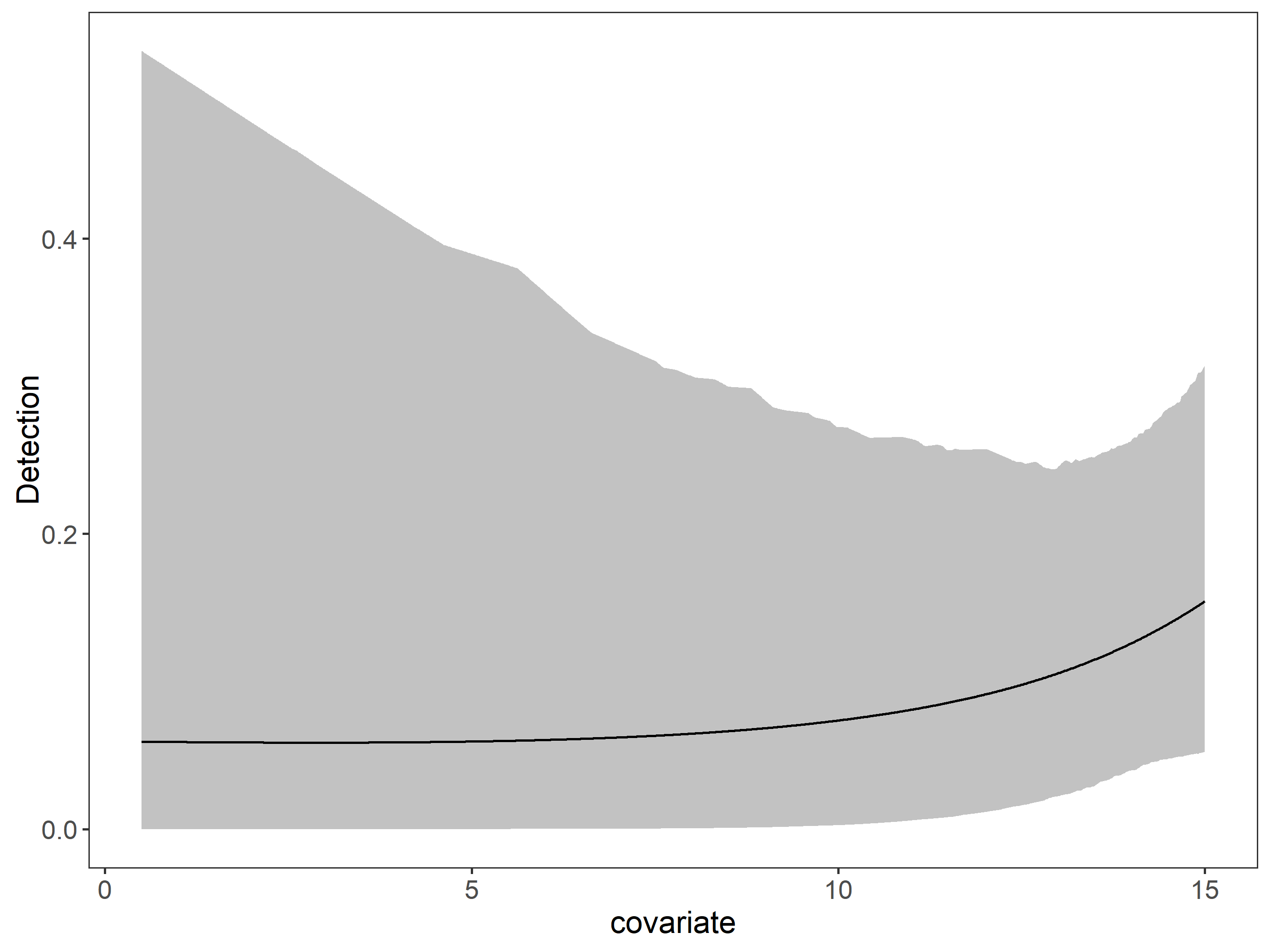
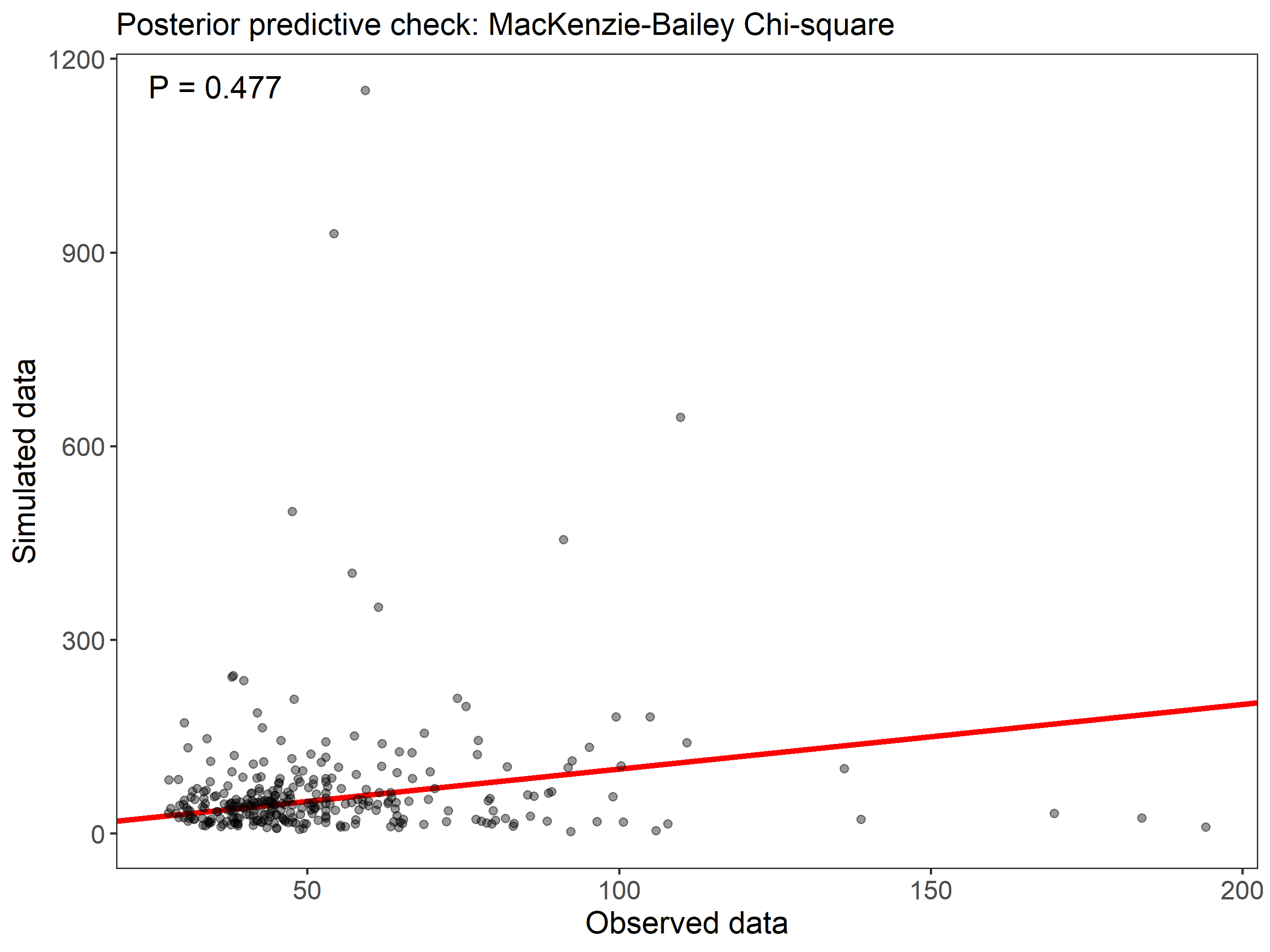
Instead of AIC, models are compared using leave-one-out cross-validation (LOO) (Vehtari, Gelman, and Gabry 2017) via the loo package. Based on this cross-validation, the expected predictive accuracy (elpd) for each model is calculated. The model with the largest elpd (effort_cattle) performed best. The looic value is analogous to AIC.
Code
loo(fit_j4)#> #> Computed from 75000 by 53 log-likelihood matrix.#> #> Estimate SE#> elpd_loo -54.8 13.5#> p_loo 4.3 1.0#> looic 109.5 27.0#> ------#> MCSE of elpd_loo is 0.0.#> MCSE and ESS estimates assume MCMC draws (r_eff in [0.1, 0.7]).#> #> All Pareto k estimates are good (k < 0.7).#> See help('pareto-k-diagnostic') for details.
Best model is effort_cattle (fit_j4) which has effort on detection and percent tree cover on occupancy.
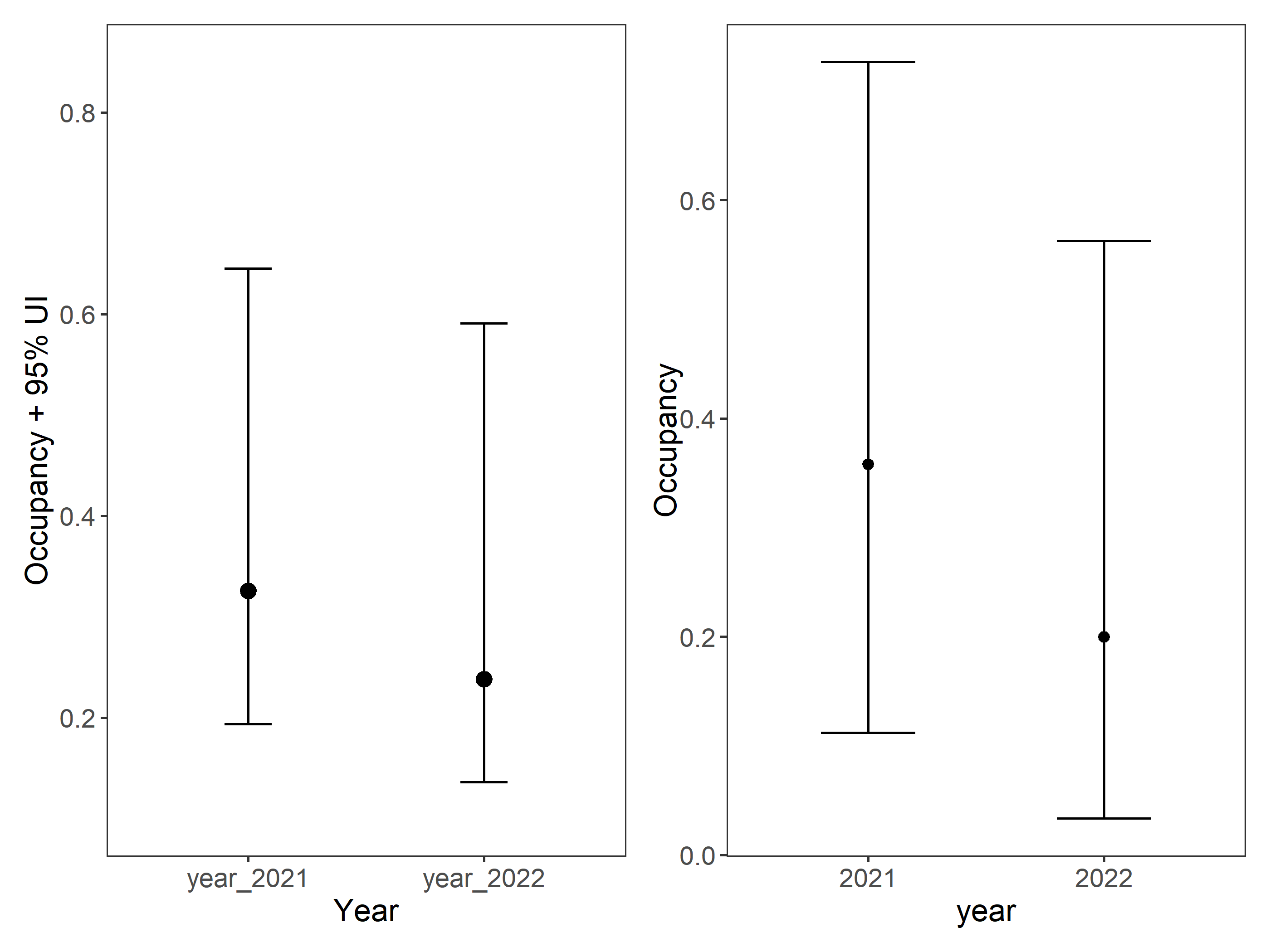
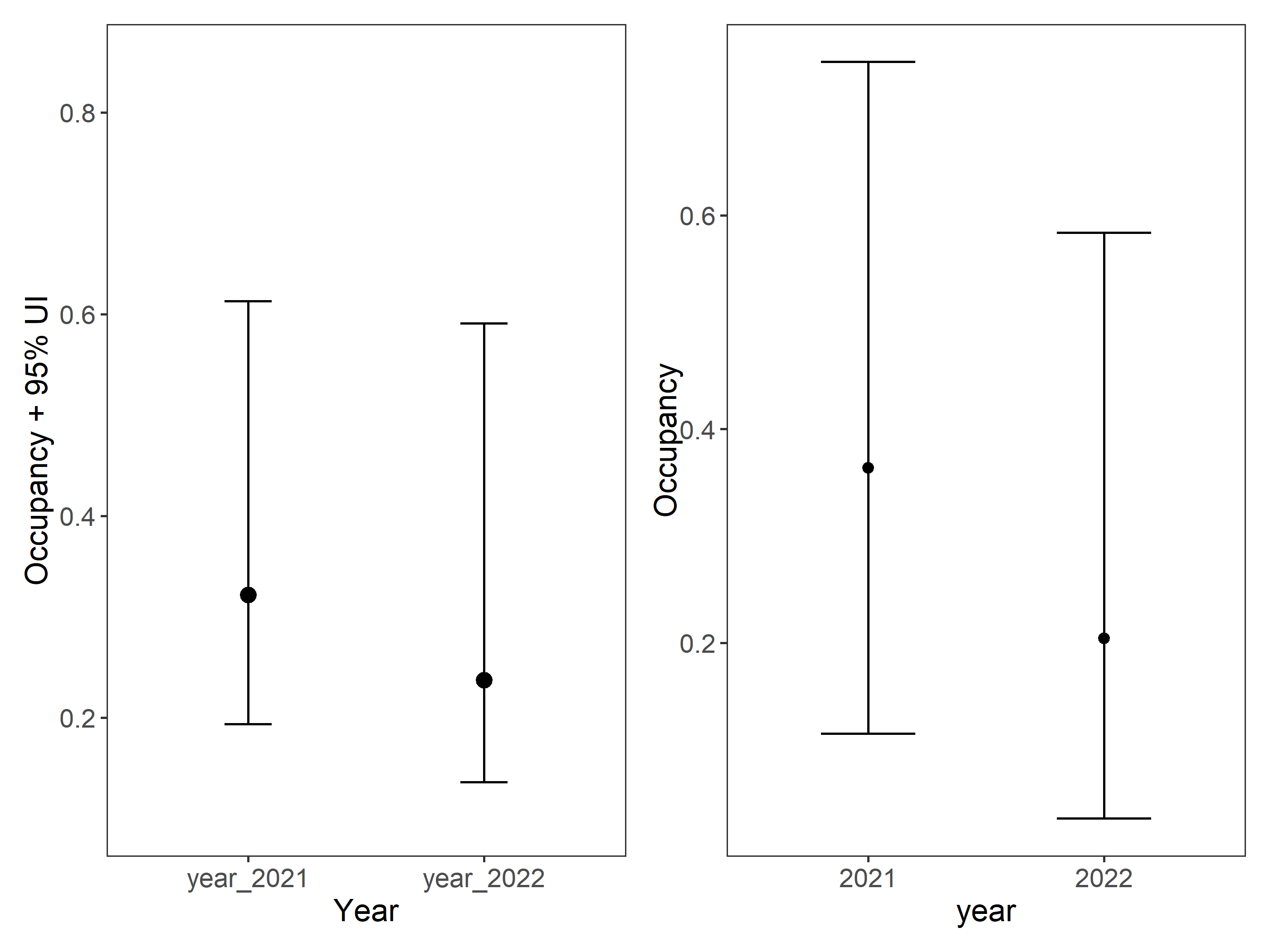
Using the posterior_predict function in ubms, you can generate an equivalent posterior distribution of z, and latter to do a post-hoc analyses to test for a difference in mean occupancy probability between sites 2021 and sites 2022.
It seems to be better to extract the years from the posteriors.
Lets make a Bayes two Sample t-test to check differences in posteriors of occupancy between years
For this we use the old but reliable BayesianFirstAid package. Notice you need to install the package from github. The goal of Bayesian First Aid is to bring in some of the benefits of cookbook solutions and make it easy to start doing Bayesian data analysis. The target audience is people that are curious about Bayesian statistics, that perhaps have some experience with classical statistics and that would want to see what reasonable Bayesian alternatives would be to their favorite statistical tests.
Code
posterior_totest<-data.frame(posterior_occu=as.vector(c(year_2021, year_2022)))posterior_totest$year<-as.factor(c(rep("2021",1000), rep("2022",1000)))# # devtools::install_github("rasmusab/bayesian_first_aid")library(BayesianFirstAid)fit<-bayes.t.test(year_2021, year_2022)print(fit)#> #> Bayesian estimation supersedes the t test (BEST) - two sample#> #> data: year_2021 (n = 1000) and year_2022 (n = 1000)#> #> Estimates [95% credible interval]#> mean of year_2021: 0.30 [0.29, 0.30]#> mean of year_2022: 0.20 [0.20, 0.21]#> difference of the means: 0.094 [0.086, 0.10]#> sd of year_2021: 0.078 [0.072, 0.084]#> sd of year_2022: 0.071 [0.066, 0.077]#> #> The difference of the means is greater than 0 by a probability of >0.999 #> and less than 0 by a probability of <0.001plot(fit)
Code
# traditional anova# anov <- glm(posterior_occu ~ year, data = posterior_totest)# Another Bayes t test# library(bayesAB)# AB1 <- bayesTest(as.vector(year_2021), # as.vector(year_2022), # priors = c('mu' = 0.5, # 'lambda' = 1, # 'alpha' = 3, # 'beta' = 1), # distribution = 'normal')# summary(AB1)# plot(AB1)
Lets make a similar test using Bayes Factors
However this time we test if occupancy from the posteriors in 2022 is < than occupancy from the posteriors in 2021.
Appelhans, Tim, Florian Detsch, Christoph Reudenbach, and Stefan Woellauer. 2025. mapview: Interactive Viewing of Spatial Data in r. https://CRAN.R-project.org/package=mapview.
Bååth, Rasmus. 2013. “Bayesian First Aid.”Tba. tba.
Bates, Douglas, Martin Mächler, Ben Bolker, and Steve Walker. 2015. “Fitting Linear Mixed-Effects Models Using lme4.”Journal of Statistical Software 67 (1): 1–48. https://doi.org/10.18637/jss.v067.i01.
Ben-Shachar, Mattan S., Daniel Lüdecke, and Dominique Makowski. 2020. “effectsize: Estimation of Effect Size Indices and Standardized Parameters.”Journal of Open Source Software 5 (56): 2815. https://doi.org/10.21105/joss.02815.
Brilleman, SL, MJ Crowther, M Moreno-Betancur, J Buros Novik, and R Wolfe. 2018. Joint Longitudinal and Time-to-Event Models via Stan.https://github.com/stan-dev/stancon_talks/.
Gilbert, Marius, Gaëlle Nicolas, Giusepina Cinardi, et al. 2018. “Global distribution data for cattle, buffaloes, horses, sheep, goats, pigs, chickens and ducks in 2010.”Scientific Data 5 (1): 180227. https://doi.org/10.1038/sdata.2018.227.
Goodrich, Ben, Jonah Gabry, Imad Ali, and Sam Brilleman. 2025. rstanarm: Bayesian Applied Regression Modeling via Stan.https://mc-stan.org/rstanarm/.
Hollister, Jeffrey, Tarak Shah, Jakub Nowosad, Alec L. Robitaille, Marcus W. Beck, and Mike Johnson. 2023. elevatr: Access Elevation Data from Various APIs. https://doi.org/10.5281/zenodo.8335450.
Kellner, Kenneth F., Nicholas L. Fowler, Tyler R. Petroelje, Todd M. Kautz, Dean E. Beyer, and Jerrold L. Belant. 2021. “ubms: An R Package for Fitting Hierarchical Occupancy and n-Mixture Abundance Models in a Bayesian Framework.”Methods in Ecology and Evolution 13: 577–84. https://doi.org/10.1111/2041-210X.13777.
Makowski, Dominique, Mattan S. Ben-Shachar, and Daniel Lüdecke. 2019. “bayestestR: Describing Effects and Their Uncertainty, Existence and Significance Within the Bayesian Framework.”Journal of Open Source Software 4 (40): 1541. https://doi.org/10.21105/joss.01541.
Meijer, Johan R, Mark A J Huijbregts, Kees C G J Schotten, and Aafke M Schipper. 2018. “Global patterns of current and future road infrastructure.”Environmental Research Letters 13 (6): 64006. https://doi.org/10.1088/1748-9326/aabd42.
Niedballa, Jürgen, Rahel Sollmann, Alexandre Courtiol, and Andreas Wilting. 2016. “camtrapR: An r Package for Efficient Camera Trap Data Management.”Methods in Ecology and Evolution 7 (12): 1457–62. https://doi.org/10.1111/2041-210X.12600.
Pebesma, Edzer. 2018. “Simple Features for R: Standardized Support for Spatial Vector Data.”The R Journal 10 (1): 439–46. https://doi.org/10.32614/RJ-2018-009.
R Core Team. 2024. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing. https://www.R-project.org/.
Wickham, Hadley, Mara Averick, Jennifer Bryan, et al. 2019. “Welcome to the tidyverse.”Journal of Open Source Software 4 (43): 1686. https://doi.org/10.21105/joss.01686.
Xie, Yihui, J. J. Allaire, and Garrett Grolemund. 2018. R Markdown: The Definitive Guide. Chapman; Hall/CRC. https://bookdown.org/yihui/rmarkdown.
Xie, Yihui, Joe Cheng, Xianying Tan, and Garrick Aden-Buie. 2025. DT: A Wrapper of the JavaScript Library “DataTables”. https://CRAN.R-project.org/package=DT.
@online{j._lizcano2024,
author = {J. Lizcano, Diego and F. González-Maya, José},
title = {“{Stacked}” {Models}},
date = {2024-07-17},
url = {https://dlizcano.github.io/cameratrap/posts/2024-07-17-stackmodel/},
langid = {en}
}