
Tratando de entender mejor la política Ecuatoriana.
Luego de varios meses en Manta, Ecuador, trabajando como investigador del DCI-ULEAM http://www.uleam.edu.ec/ en el proyecto Fauna de Manabí http://faunamanabi.github.io/. La universidad para la que laboro fue intervenida por el gobierno. Ahora yo me imagino que muchas de las decisiones y reformas que se implementen en la ULEAM estarán alineadas con la política del gobierno.
Como extranjero en Ecuador mi relación con la política Ecuatoriana es lejana. Pero de lo poco que se, el gobierno de Rafael Correa tiene una política muy amigable con la educación, de hecho han creado varias universidades nuevas, han implementado políticas novedosas e invertido buenos recursos para atraer investigadores y docentes extranjeros a las universidades del Ecuador. A esto se le ha sumado un programa de becas que envía a ecuatorianos a estudiar a las mejores universidades del mundo.
Con este “post” de mi blog, quiero usar las técnicas de minería de texto y el mismo clasificador de sentimientos de una entrada anterior, para analizar un discurso de René Ramírez, el actual Secretario de Educación Superior Ciencia, Tecnología e Innovación SENECYT y Presidente del Consejo de Educación Superior CES. Quien por cierto es bien activo en twitter, como @compaiRENE. El discurso se titula: La disputa política por el sentido del (bio)conocimiento y lo descargue de su página web.
Si bien el análisis de sentimientos es bien controversial por su aparente falta de rigor estadístico y por la debilidad de su clasificador bayesiano “naive”, que por cierto, ahora me entero, se traduce como ingenuo (me encanta esa traducción!). El hecho es que a pesar de ser polémico, este tipo de análisis, es una poderosa herramienta de análisis de mercados, usada por muchas empresas de minería de datos.
El discurso fue analizado dividiendolo en 3 partes y por párrafos. A cada párrafo se le asignó un puntaje dependiendo de las palabras usadas y que tan positiva o negativa es la palabra, comparada con un corpus hibrido en español que he ido construyendo, el cual ya tiene mas de 3300 palabras. Y aquí el resultado:
Polaridad
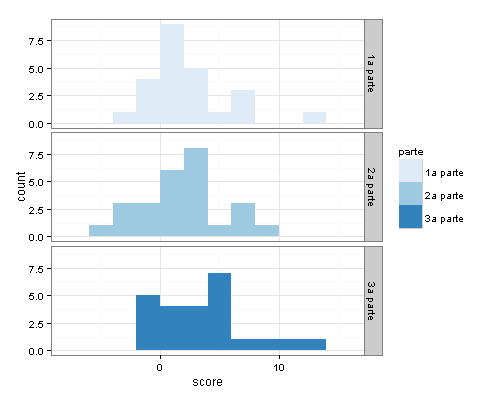
Curiosamente a medida que avanza el discurso, este se hace más positivo (score mayor que cero).
Análisis de sentimientos
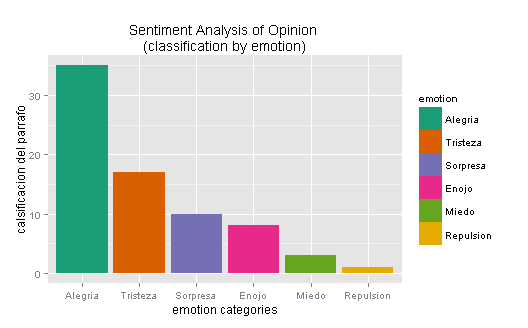
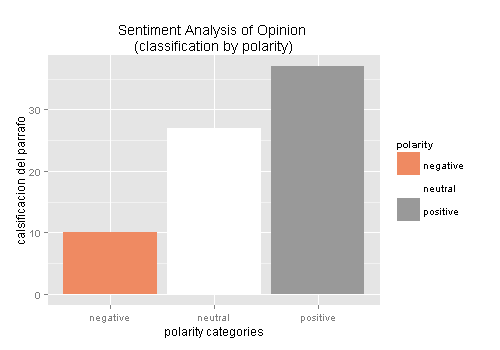
Sorprendentemente muchos de sus párrafos son alegres, seguido por algunos tristes. Pero en términos generales el discurso es positivo, neutral, tal como se ve en la próxima gráfica.
Polaridad global
Y la infaltable nube de palabras

Si desea repetir este análisis o hacer uno parecido. Acá está el código de R:
Discurso <- read.csv("discurso_rene.txt", header = F)
Discurso$text<-as.factor(Discurso$V1)
Discurso.scores = score.sentiment(Discurso$text, pos.words,neg.words, .progress='text')
hist(Discurso.scores$score)
#################################
#Chunk -6- Comparing 3 data sets
#################################
Discurso.scores$parte<-NA
Discurso.scores$parte[1:24]<-"1a parte"
Discurso.scores$parte[25:50]<-"2a parte"
Discurso.scores$parte[51:74]<-"3a parte"
all.scores = rbind(Discurso.scores)#, Jaime.scores.programas)#, Cucuta.scores)
ggplot(data=all.scores) + # ggplot works on data.frames, always
geom_bar(mapping=aes(x=score, fill=parte), binwidth=2) +
facet_grid(parte~.) + # make a separate plot for each hashtag
theme_bw() + scale_fill_brewer() # plain display, nicer colors
########################################
library(plyr)
library(ggplot2)
library(wordcloud)
library(RColorBrewer)
emo_polari <- function (Texto.dataframe) { #Start function
# Get the text
# Texto_txt = sapply(Texto.list, function(x) x$getText())
Texto_txt = Texto.dataframe$text
# Prepare text for the analysis
Texto_txt = gsub("(RT|via)((?:\\b\\W*@\\w+)+)", "", Texto_txt)
Texto_txt = gsub("@\\w+", "", Texto_txt)
Texto_txt = gsub("[[:punct:]]", "", Texto_txt)
Texto_txt = gsub("[[:digit:]]", "", Texto_txt)
Texto_txt = gsub("http\\w+", "", Texto_txt)
Texto_txt = gsub("[ \t]{2,}", "", Texto_txt)
Texto_txt = gsub("^\\s+|\\s+$", "", Texto_txt)
try.error = function(x)
{
# create missing value
y = NA
# tryCatch error
try_error = tryCatch(tolower(x), error=function(e) e)
# if not an error
if (!inherits(try_error, "error"))
y = tolower(x)
# result
return(y)
}
# lower case using try.error with sapply
Texto_txt = sapply(Texto_txt, try.error)
# remove NAs in Texto_txt
Texto_txt = Texto_txt[!is.na(Texto_txt)]
names(Texto_txt) = NULL
#classify emotion
class_emo = classify_emotion(Texto_txt, algorithm="bayes", prior=1.0)
#get emotion best fit
emotion = class_emo[,7]
# substitute NA's by "unknown"
emotion[is.na(emotion)] = "unknown"
# classify polarity
class_pol = classify_polarity(Texto_txt, algorithm="bayes")
# get polarity best fit
polarity = class_pol[,4]
# data frame with results
sent_df = data.frame(text=Texto_txt, emotion=emotion,
polarity=polarity, stringsAsFactors=FALSE)
# sort data frame
sent_df = within(sent_df,
emotion <- factor(emotion, levels=names(sort(table(emotion), decreasing=TRUE))))
# plot distribution of emotions
emocion<- ggplot(sent_df, aes(x=emotion)) +
geom_bar(aes(y=..count.., fill=emotion)) +
scale_fill_brewer(palette="Dark2") +
labs(x="emotion categories", y="calsificacion del parrafo",
title = "Sentiment Analysis of Opinion \n(classification by emotion)",
plot.title = element_text(size=12))
print(emocion)
# plot distribution of polarity
polaridad<- ggplot(sent_df, aes(x=polarity)) +
geom_bar(aes(y=..count.., fill=polarity)) +
scale_fill_brewer(palette="RdGy") +
labs(x="polarity categories", y="calsificacion del parrafo",
title = "Sentiment Analysis of Opinion \n(classification by polarity)",
plot.title = element_text(size=12))
print(polaridad)
}#end of function
emo_polari(Discurso.scores)
###### wordcloud
mh370_corpus = Corpus(VectorSource(Discurso.scores$text))
tdm = TermDocumentMatrix(
mh370_corpus,
control = list(
removePunctuation = TRUE,
stopwords = c("prayformh370", "prayformh", stopwords("spanish")),
removeNumbers = TRUE, tolower = TRUE)
)
m = as.matrix(tdm)
# get word counts in decreasing order
word_freqs = sort(rowSums(m), decreasing = TRUE)
# create a data frame with words and their frequencies
dm = data.frame(word = names(word_freqs), freq = word_freqs)
wordcloud(dm$word, dm$freq, random.order = FALSE, colors = brewer.pal(10, "Dark2"))
Cosas que uno hace cuando esta solo en Ecuador y la TV no muestra nada bueno!… jejejejeje…

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.

Leave a comment