Code
library(readxl)
library(grateful)
library(DT)
library(sf)
library(mapview)
library(maps)
library(tmap)
library(terra)
library(elevatr)
library(unmarked)
library(ubms)
library(tidyverse)
source("C:/CodigoR/WCS-CameraTrap/R/organiza_datos.R")WCS camera trap dataset
Diego Lizcano 
Obtener datos para estudios de poblaciones animales, es costoso y dispendioso, y no siempre se puede medir la densidad poblacional o parámetros demográficos como natalidad o mortalidad.
En este panorama surge la estimación de la ocupación (la cual vamos a llamar Psi (ψ)), como una buena herramienta para entender las poblaciones. Usualmente parámetros poblacionales como la abundancia y la densidad, requieren de un elevado número de registros, y tomar datos con un diseño especifico, con los costos económicos y logísticos que conlleva.
Adicionalmente y debido a que la detectabilidad (la cual vamos a llamar (p)) en animales silvestres no es perfecta, el uso de los datos crudos genera subestimaciones de la ocupación. Sin embargo con el empleo de muestreos repetidos, es posible generar estimaciones del error de detección y, con esta estimación, obtener valores no sesgados de la ocupación. Los métodos de análisis de la ocupación fueron inicialmente desarrollados por (MacKenzie et al., 2002) y posteriormente expandidos por otros autores (M. Kéry & Royle, 2008; MacKenzie et al., 2006; MacKenzie & Royle, 2005; Royle, 2006; Royle & Kéry, 2007; Royle, Nichols, Kéry, 2005).
Para aprender con mas detalle sobre la ocupación, te recomiendo seguir este tutorial en español.
A continuacion vamos a hacer un analisis de ocupación sencillo usando los datos del Jaguar Camera Trap Survey, Tuichi 8, 2019 del archivo BOL-038.xlsx
library(readxl)
library(grateful)
library(DT)
library(sf)
library(mapview)
library(maps)
library(tmap)
library(terra)
library(elevatr)
library(unmarked)
library(ubms)
library(tidyverse)
source("C:/CodigoR/WCS-CameraTrap/R/organiza_datos.R")Para esto usamos las funciones loadproject y get.sites.
# load data
bol038 <- loadproject("C:/CodigoR/WCS-CameraTrap/data/Bolivia/BOL-038.xlsx")
# get sites
bol038_sites <- get.sites("C:/CodigoR/WCS-CameraTrap/data/Bolivia/BOL-038.xlsx")
# make a map
mapview(bol038_sites, zcol="bait")datatable(as.data.frame( sort(table(bol038$scientificName))))No te ausutes! no son del espacio exterior! con espaciales quiero decir que son covariables que se pueden obtener de un mapa.
Usaremos el mapa de puntos (bol038_sites) para extraer el porcentaje de cobertura vegetal del anio 2019 de MODIS, el mapa de cobertura de la tierra del anio 2019 de MODIS y la elevación.
# get elevation map
elevation <- rast(get_elev_raster(bol038_sites, z = 9))
bb <- st_as_sfc(st_bbox(elevation)) # make bounding box
land_cover_large <- rast("C:/CodigoR/WCS-CameraTrap/raster/latlon/LandCover_Type_Yearly_500m_v61/LC1/MCD12Q1_LC1_2019_001.tif")
#### convert 200=water;253=fill to ceros
per_tree_cover_large <- rast("C:/CodigoR/WCS-CameraTrap/raster/latlon/Veg_Cont_Fields_Yearly_250m_v61/Perc_TreeCov/MOD44B_Perc_TreeCov_2019_065.tif")
#
land_cover <- terra::crop(land_cover_large, elevation, snap="near") # cut to elevation
per_tre_cover <- terra::crop(per_tree_cover_large, elevation, snap="near") # cut to elevation
# project to elevation
land_cover_p <- terra::project(x = land_cover, y = elevation, method="near")
per_tre_cover_p <- terra::project(x = per_tre_cover, y = elevation, method="bilinear")
ext(land_cover_p)<-ext(elevation)
ext(per_tre_cover_p)<-ext(elevation)
#resample<-dimension and resolution fits but values change
# land_cover_p<-resample(land_cover,elevation)
# remove the large maps
rm(per_tree_cover_large, land_cover_large)
# make a stack
covs_map <- rast(list(elevation, land_cover_p, per_tre_cover_p))
# rename
names(covs_map) <- c("elevation", "land_cover", "per_tre_cover")
plot(covs_map)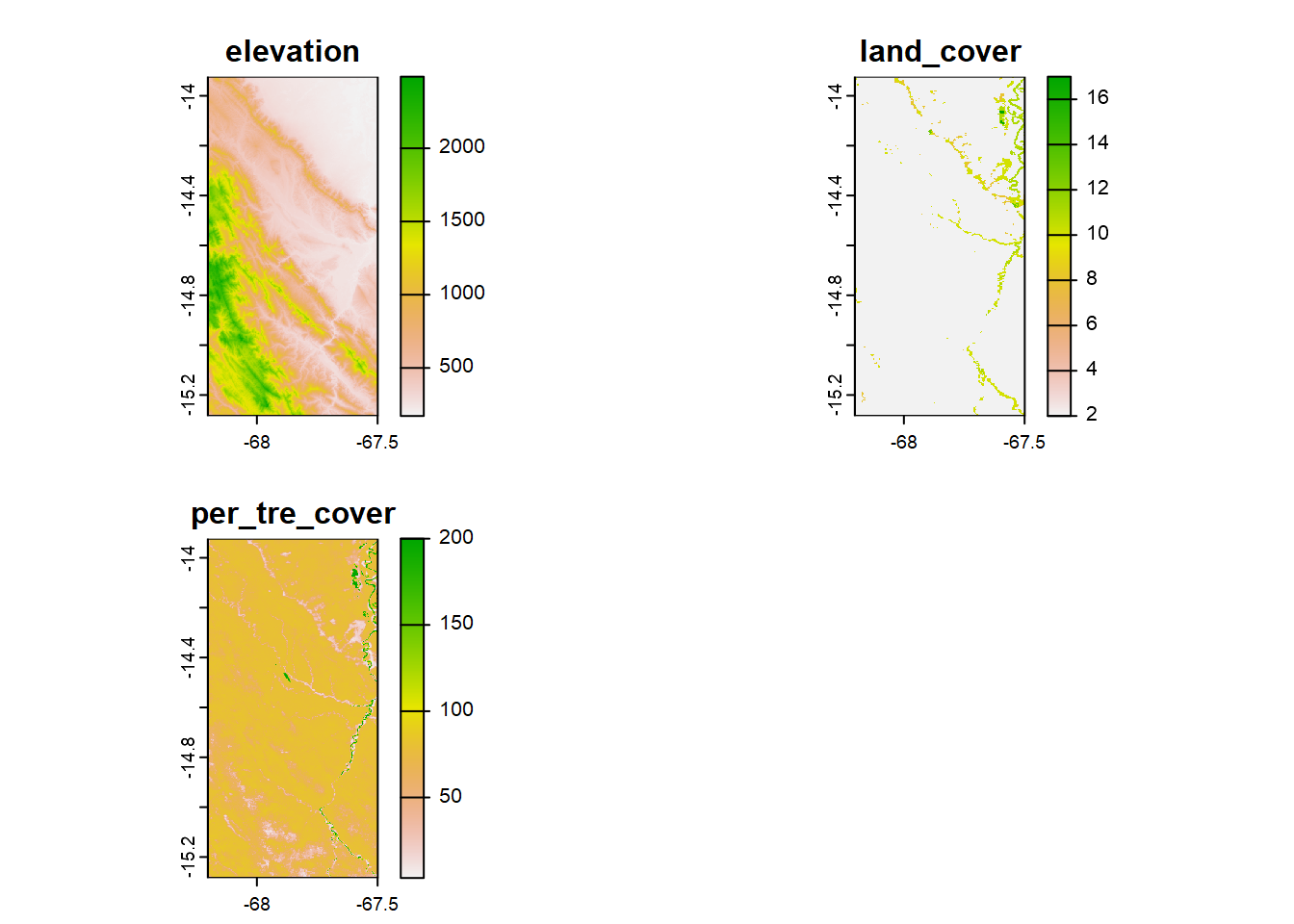
# extract covs using points and add to bol038_sites
covs <- cbind(bol038_sites, terra::extract(covs_map, bol038_sites))
# remove decimals convert to factor
covs$land_cover <- as.factor(floor(covs$land_cover))En este caso lo haremmos para el Jaguar. Para esto usaremos la función f.det_history.creator, la cual crea una lista con todas las historias de deteccion por dia, de todas las especies y luego extraemos al jaguar.
posteriormente usamos el paquete unmarked para adicionar la historia de detección al analisis y calcular la probabilidad de deteccion y la ocupación.
historias <- f.det_history.creator(data=bol038, year=2019)
sp_number <- which(names(historias)=="Panthera onca")#arrange detections observations
x4_bait <- cbind(as.data.frame(bol038_sites), replicate(49, bol038_sites$bait))
x4_CamType <- cbind(as.data.frame(bol038_sites), replicate(49, bol038_sites$CamTypes))
x4_ObsCovs_list <- list(bait= as.data.frame(x4_bait[,5:52]),
CamTypes= as.data.frame(x4_CamType[,5:52]))
# Make UMF object
umf <- unmarkedFrameOccu(y= as.data.frame (historias[[sp_number]]),
siteCovs = as.data.frame(covs),
obsCovs = x4_ObsCovs_list
)
# saveRDS(umf, "C:/CodigoR/WCS_2024/camera_trap/R/umf.rds")
plot(umf, main="Panthera onca") 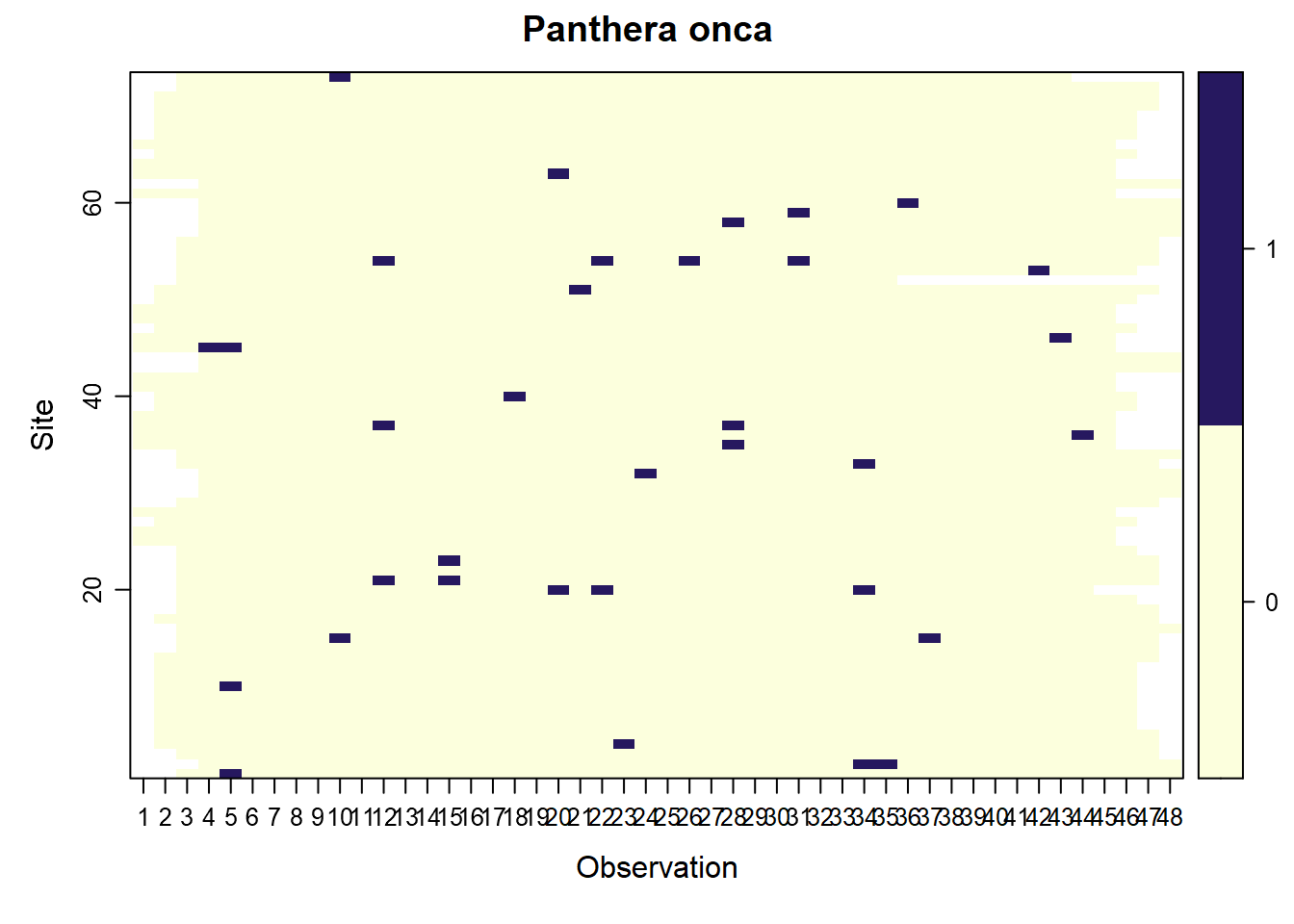
La función occu ajusta el modelo de ocupación estándar single season occupancy model basado en modelos binomiales inflados a cero (MacKenzie et al. 2006, Royle y Dorazio 2008).
Vea mas detalles de lo que hace esta funcion y las ecuaciones que hay detras escribiendo en su consola: ?occu o siguiendo este tutorial en español.
# fit unmarked models
fit_1 <- unmarked::occu(~1~1, data=umf) # ok!
fit_2 <- unmarked::occu(~factor(bait) ~1, data=umf) # It work!
fit_3 <- unmarked::occu(~factor(CamTypes) ~1, data=umf) # It work!
fit_4 <- unmarked::occu(~1~scale(elevation), data=umf) # It work!
fit_5 <- unmarked::occu(~1~factor(land_cover), data=umf) # Hessian problem!
fit_6 <- unmarked::occu(~1~scale(per_tre_cover), data=umf)# It work!
# model names
# fit list for detection
fms1<-fitList("p(.) Ocu(.)"= fit_1,
"p(bait) Ocu(.)"= fit_2,
"p(CamType) Ocu(.)"= fit_3,
"p(.) Ocu(elevation)"= fit_4,
"p(.) Ocu(land_cover)"= fit_5,
"p(.) Ocu(per_tre_cover)"=fit_6)
# model selection detection unmarked
ms1<- modSel(fms1)
#> Hessian is singular.
ms1
#> nPars AIC delta AICwt cumltvWt
#> p(CamType) Ocu(.) 3 380.91 0.00 0.37736 0.38
#> p(bait) Ocu(.) 4 381.84 0.93 0.23658 0.61
#> p(.) Ocu(.) 2 382.21 1.30 0.19704 0.81
#> p(.) Ocu(elevation) 3 383.26 2.35 0.11635 0.93
#> p(.) Ocu(per_tre_cover) 3 384.21 3.30 0.07249 1.00
#> p(.) Ocu(land_cover) 9 396.21 15.30 0.00018 1.00
# to see in html
toExport <- as(ms1, "data.frame") # Everything
fms1_table <- toExport |> select("model", "AIC", "delta", "cumltvWt")
datatable(fms1_table)Note que hay un problema de Hessian en el modelo fit_5!
Hagamos una prueba sencilla con interpretación estadistica y visual con parboot al mejor modelo. Esta función simula conjuntos de datos basados en el modelo seleccionado, reajusta el modelo y evalúa una estadística de ajuste especificada por el usuario para cada simulación. Al comparar esta distribución con la estadística observada proporciona un medio para evaluar la bondad de ajuste o evaluar la incertidumbre de la estimación del modelo.
# Function returning the fit-statistics.
fitstats <- function(fm, na.rm=TRUE) {
observed <- getY(fm@data)
expected <- fitted(fm)
# resids <- residuals(fm)
# sse <- sum(resids^2, na.rm=na.rm)
chisq <- sum((observed - expected)^2 / expected, na.rm=na.rm)
# freeTuke <- sum((sqrt(observed) - sqrt(expected))^2, na.rm=na.rm)
out <- c(Chisq=chisq) #c(SSE=sse, Chisq=chisq, freemanTukey=freeTuke)
return(out)
}
pb <- parboot(fit_3, fitstats, nsim=300, report=1)
plot(pb, main="p(CamType) Ocu(.)")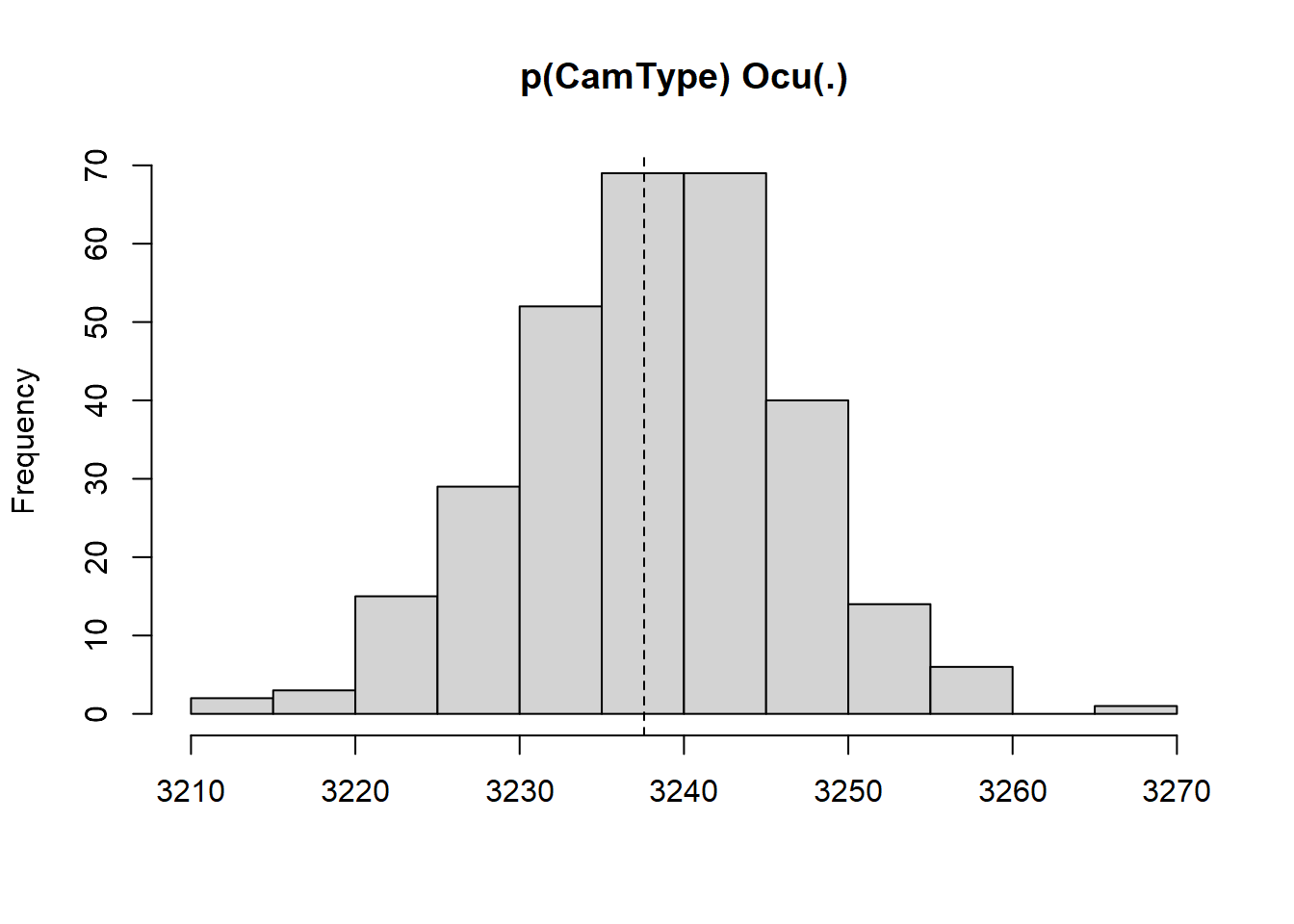
La linea punteada cae dentro de la distribución del histograma, asi que si es un modelo, con un buen ajuste que serviria para predecir.
Aca debemos tener paciencia para que el modelo converga incrementando las iteraciones a por lo menos 100 mil….
Just Wait !!!!!
# define number of iterations
itera=10000
# fit stan (Bayesian models) using the package ubms
fit_stan_1 <- stan_occu(~1~1, data=umf, chains=3, iter=itera, cores=3)
fit_stan_2 <- stan_occu(~factor(bait)~1, data=umf, chains=3, iter=itera, cores=3)
fit_stan_3 <- stan_occu(~factor(CamTypes)~1, data=umf, chains=3, iter=itera, cores=3)
fit_stan_4 <- stan_occu(~1~scale(elevation), data=umf, chains=3, iter=itera, cores=3)
fit_stan_5 <- stan_occu(~1~factor(land_cover), data=umf, chains=3, iter=itera, cores=3)
fit_stan_6 <- stan_occu(~1~scale(per_tre_cover), data=umf, chains=3, iter=itera, cores=3)
fit_stan_7 <- stan_occu(~1~scale(elevation) + factor(land_cover), data=umf, chains=3, iter=itera, cores=3)
# put name to the models
stan_mods <- fitList("p(.) Ocu(.)" = fit_stan_1,
"p(bait) Ocu(.)"= fit_stan_2,
"p(CamType) Ocu(.)"= fit_stan_3,
"p(.) Ocu(elevation)"= fit_stan_4,
"p(.) Ocu(land_cover)"= fit_stan_5,
"p(.) Ocu(per_tre_cover)"=fit_stan_6,
"p(.) Ocu(elev+land_cover)"=fit_stan_7
)
# model selection
ms2 <- round(modSel(stan_mods), 3) #AGB_Spawn
ms2
#> elpd nparam elpd_diff se_diff weight
#> p(.) Ocu(elevation) -189.116 2.723 0.000 0.000 0.688
#> p(.) Ocu(elev+land_cover) -189.173 4.245 -0.056 0.575 0.017
#> p(.) Ocu(land_cover) -189.463 3.956 -0.347 1.339 0.296
#> p(.) Ocu(.) -189.576 1.988 -0.460 1.203 0.000
#> p(.) Ocu(per_tre_cover) -190.512 3.441 -1.396 1.755 0.000
#> p(bait) Ocu(.) -190.560 3.547 -1.443 1.723 0.000
#> p(CamType) Ocu(.) -190.627 3.320 -1.511 1.273 0.000
# to see the table in html
ms2_table <- as(ms2, "data.frame") # Everything
datatable(ms2_table)El modelo con el elpd más grande “p(CamType) Ocu(.)” tuvo el mejor rendimiento. Aca la tabla tiene diferente orden que las tablas de comparar el AIC.
La columna elpd_diff muestra la diferencia en elpd entre un modelo y el modelo superior; Si esta diferencia es varias veces mayor que el error estándar de la diferencia (se_diff), estamos seguros de que el modelo con el elpd más grande tuvo un mejor desempeño.
Hagamos una prueba remuestreando con la función gof. Para cada muestreo de los posteriores, la estadística MB se calcula para los datos reales y para un conjunto de datos simulado. La proporción de muestreos para los cuales la estadística simulada es mayor que la estadística real debería ser cercana a 0,5 si el modelo se ajusta bien.
(fit_top_gof <- gof(fit_stan_3, draws=100, quiet=TRUE))
#> MacKenzie-Bailey Chi-square
#> Point estimate = 3760485.156
#> Posterior predictive p = 0.27
plot(fit_top_gof)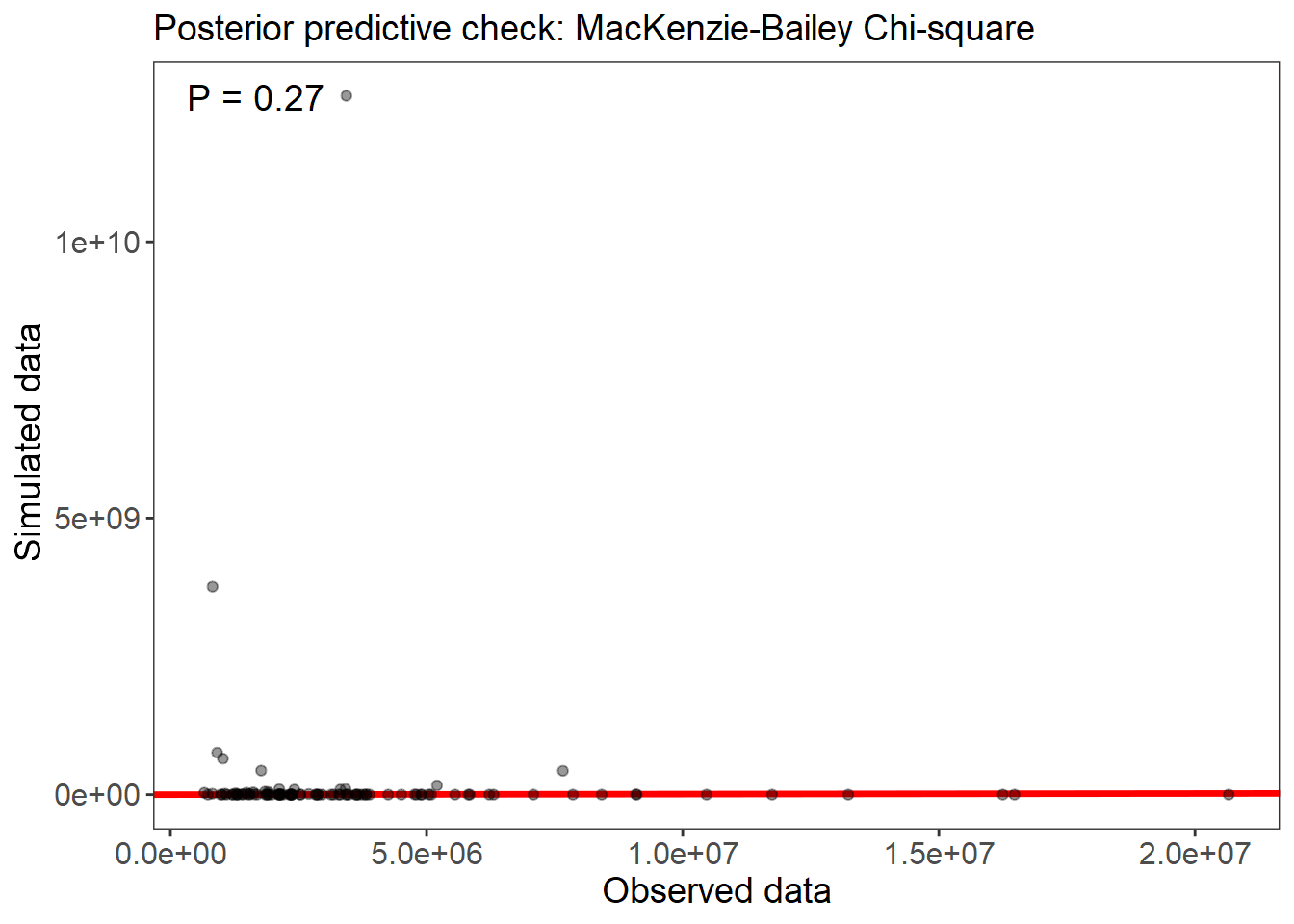
Acá la interpretación es que los puntos deben estar distribuidos alrededor de la linea y el valor P debe ser cercano a 0.5. En este caso 0.2 no esta mal, es un modelo que se puede usar para predecir, probablemente con un error grande pero dentro de los limites de lo razonable.
Veamos los detalles del modelo
(fit_stan_3)
#>
#> Call:
#> stan_occu(formula = ~factor(CamTypes) ~ 1, data = umf, chains = 3,
#> iter = itera, cores = 3)
#>
#> Occupancy (logit-scale):
#> Estimate SD 2.5% 97.5% n_eff Rhat
#> 0.587 0.806 -0.47 2.62 3608 1
#>
#> Detection (logit-scale):
#> Estimate SD 2.5% 97.5% n_eff Rhat
#> (Intercept) -3.838 0.379 -4.60 -3.115 4726 1
#> factor(CamTypes)2 -0.331 0.385 -1.07 0.446 5863 1
#>
#> LOOIC: 381.255
#> Runtime: 33.703 secRecuerque que estan en escala logit, asi que usamos plogis para convertirlo a escala normal, asi plogis(-0.33) = 0.4182406 es la probabilidad de deteccion, cuando el intercepto del tipo de camara es cero. Es una probabilidad baja tipica de un Jaguar, pero alta si se compara con otros muestreos.
La ocupación es plogis(0.587) = 0.6426765. Podriamos decir que el jaguar esta ocupando mas de 60% de los sitios muestreados.
plot_effects(fit_stan_2, "det") # Detection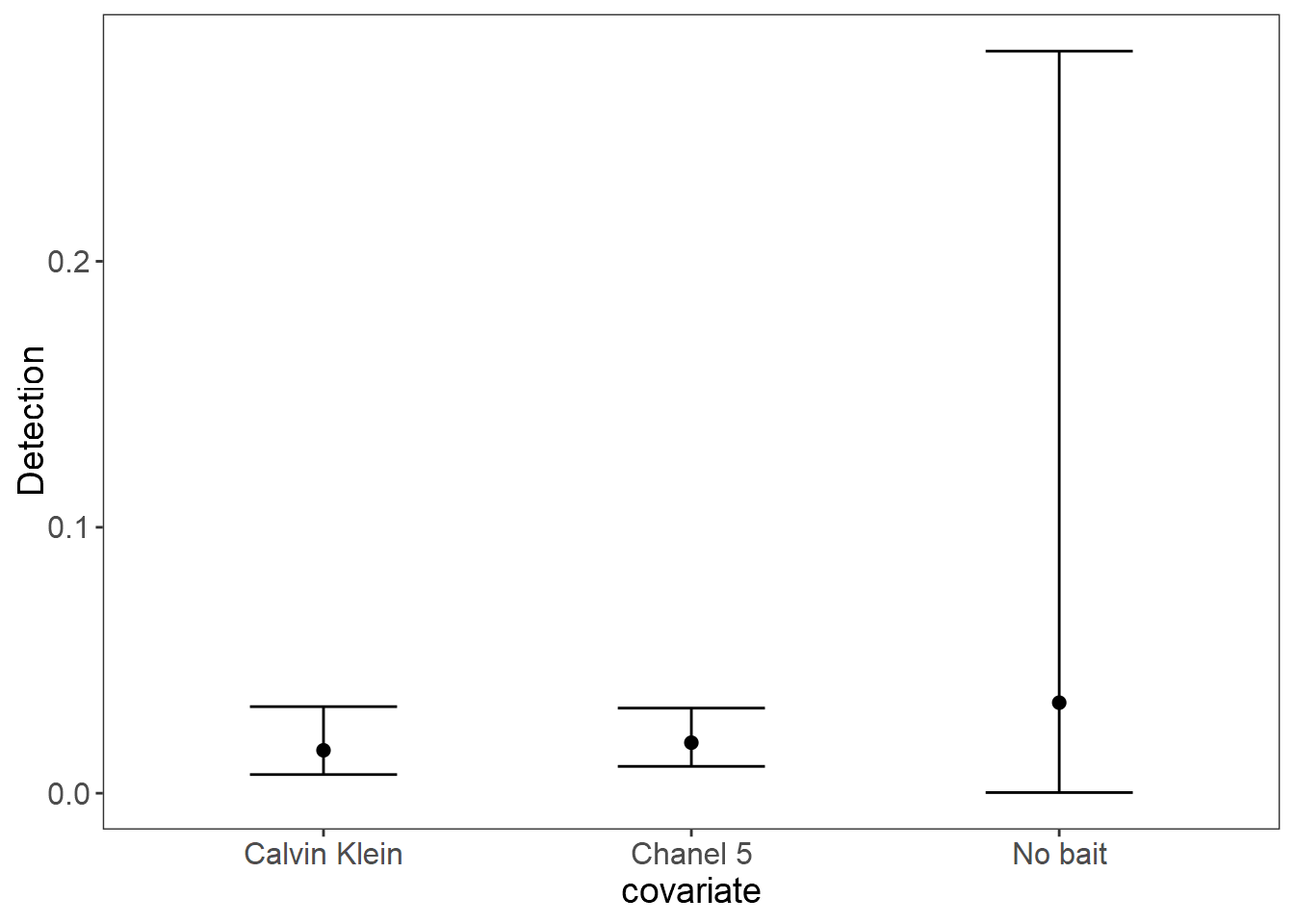
plot_effects(fit_stan_3, "det") # Detection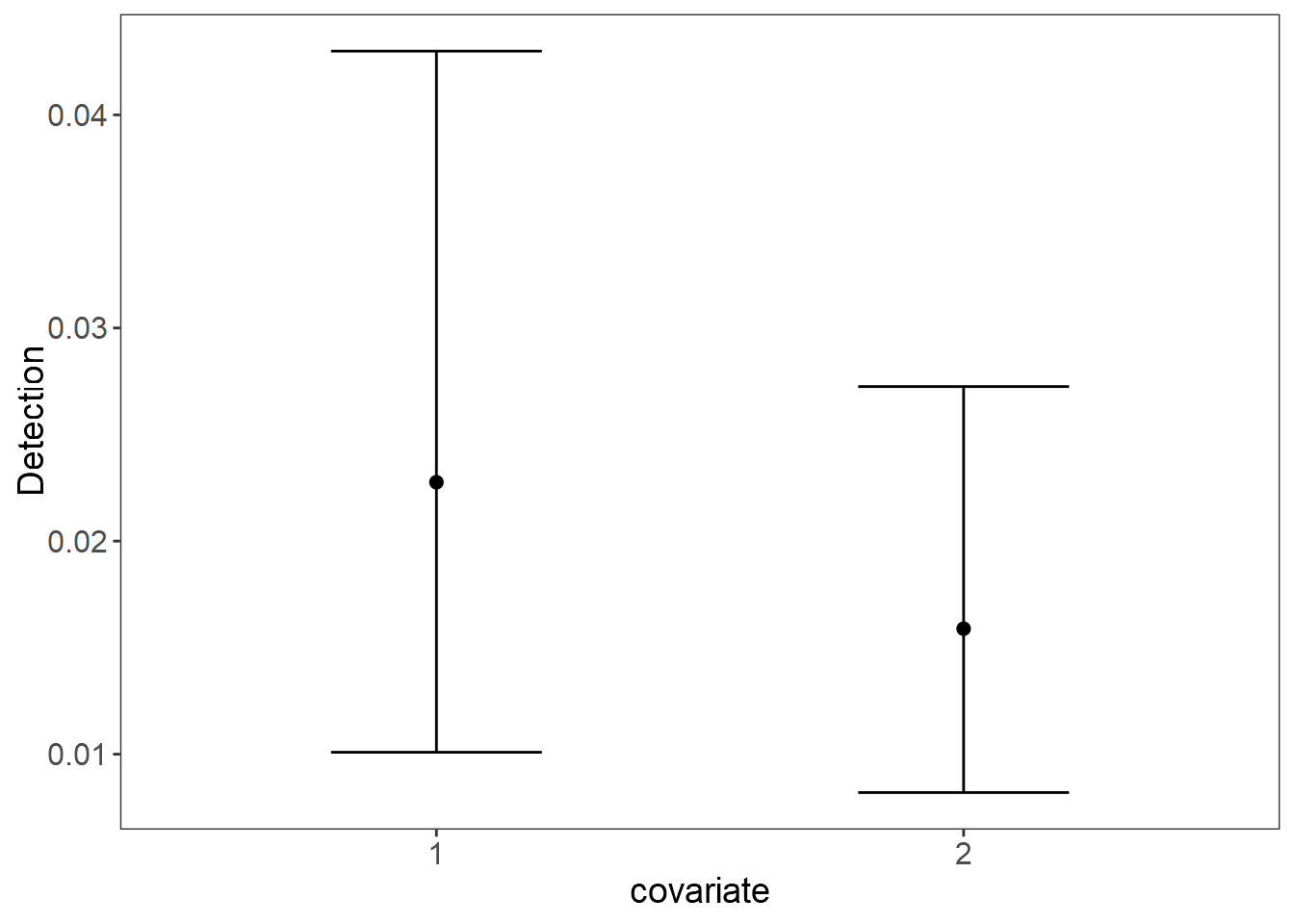
plot_effects(fit_stan_4, "state") # Ocupancy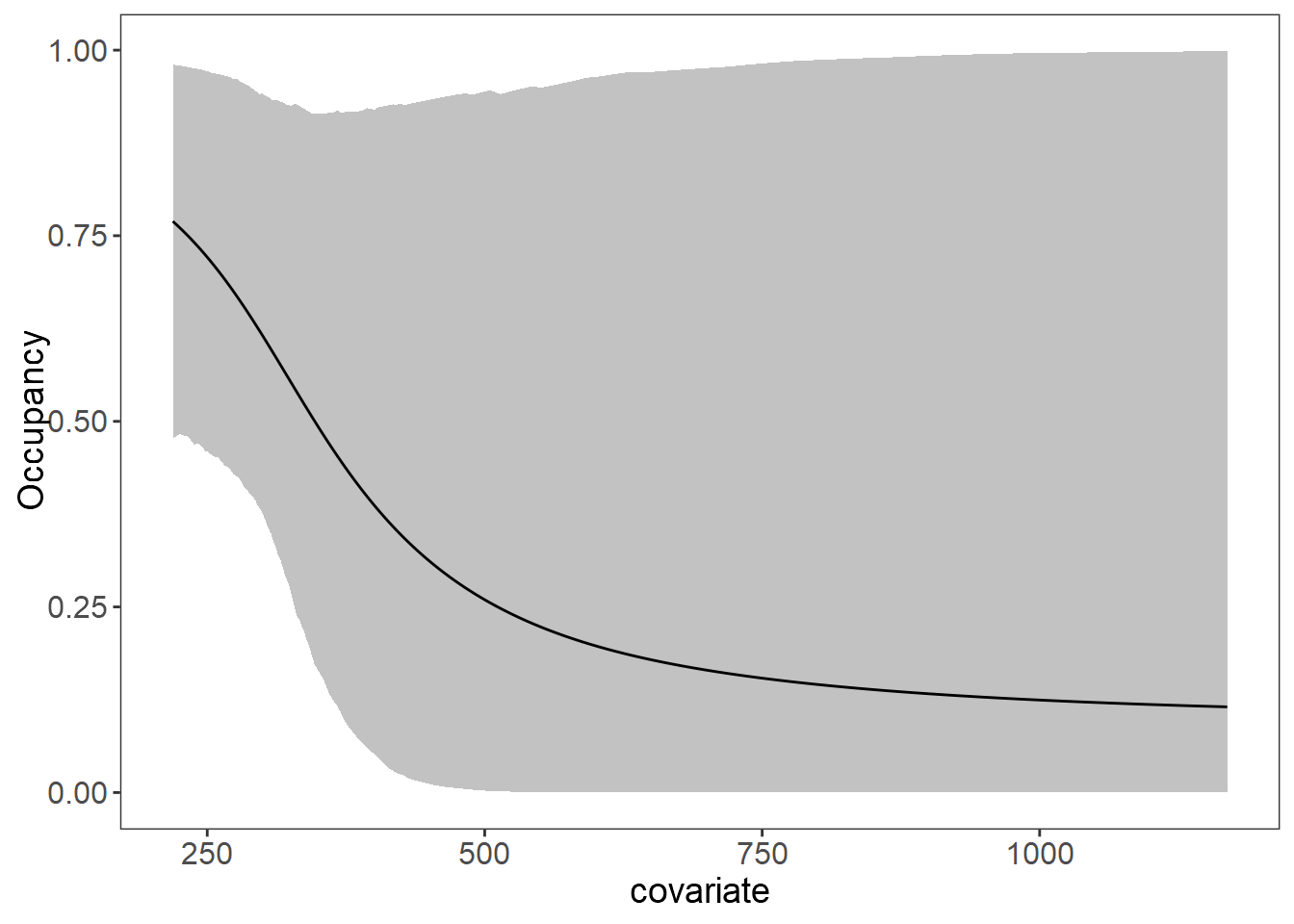
plot_effects(fit_stan_6, "state") # Ocupancy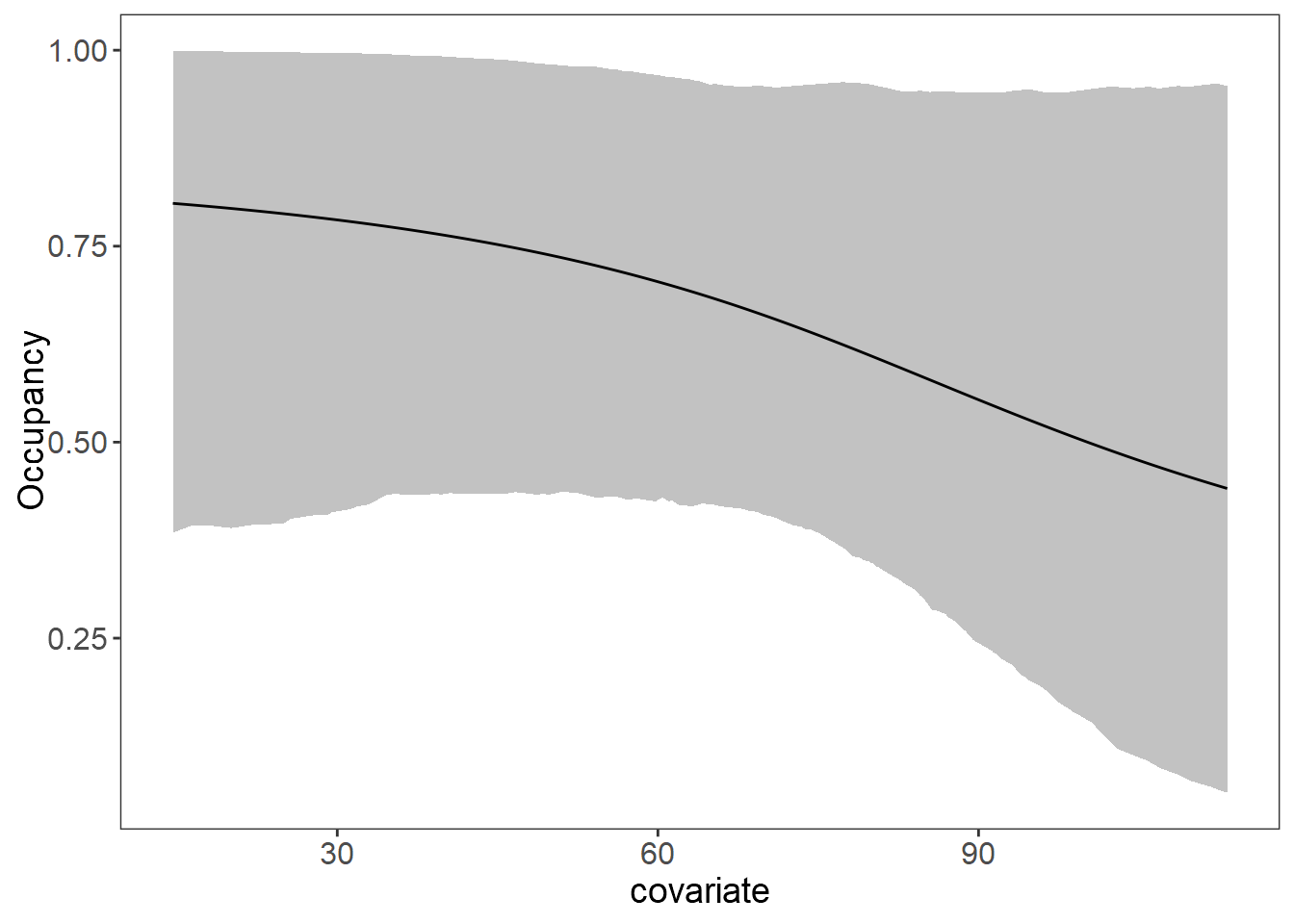
# plot top model
plot_effects(fit_stan_5, "state") # Ocupancy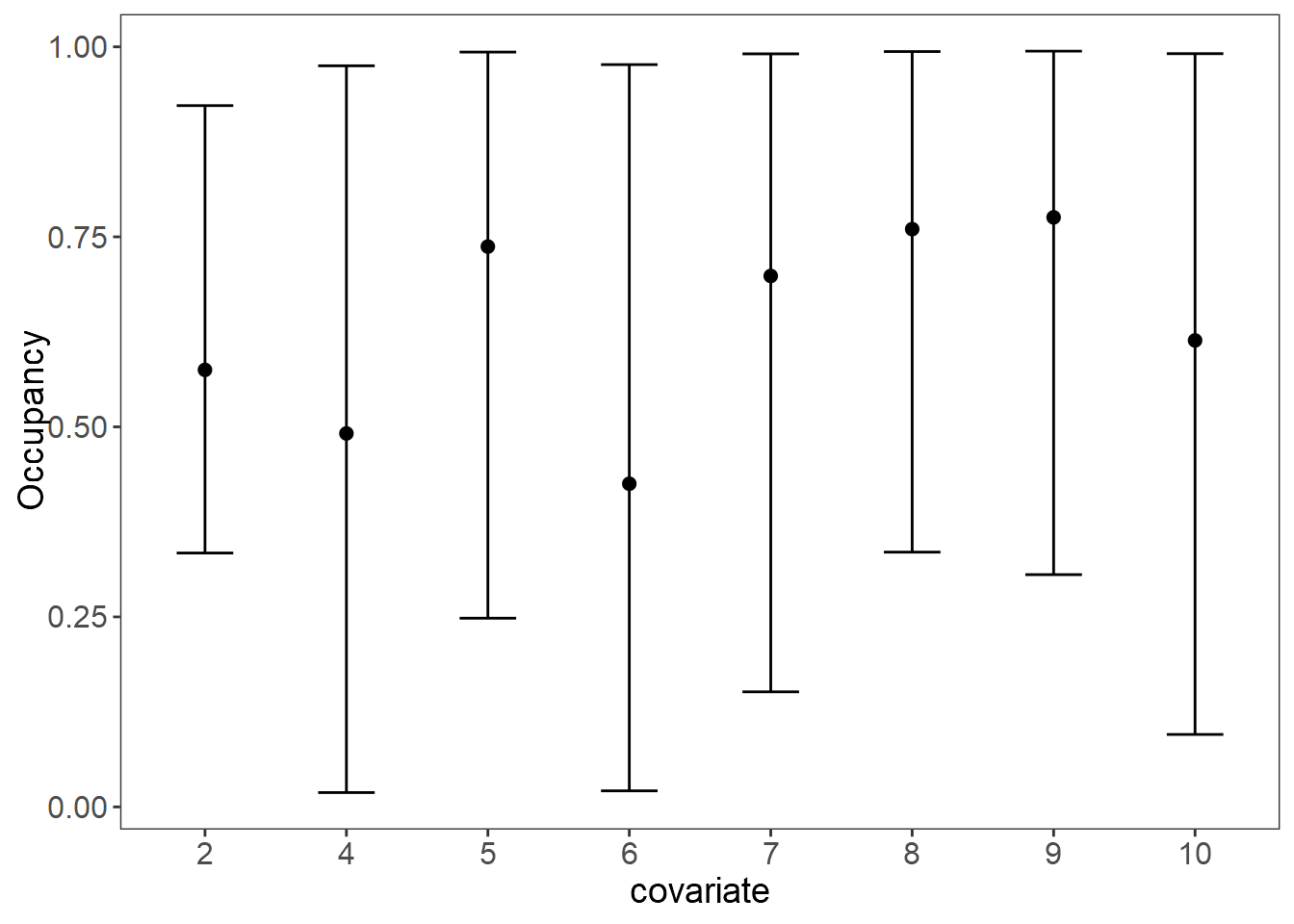
Usaremos el mapa de el porcentage de cobertura de dosel para predecir la ocupación del Jaguar.
# predict using the raster
occu_pred <- predict(fit_stan_6, submodel="state", newdata=covs_map$per_tre_cover)
# make a template raster = to covs_map$elevation
pred_map <- covs_map$elevation
# drape prediction on top
pred_map[] <- occu_pred$Predicted
# put name
names(pred_map) <- "Occupancy"
# view in map
mapview (pred_map) + mapview(bol038_sites, zcol="bait")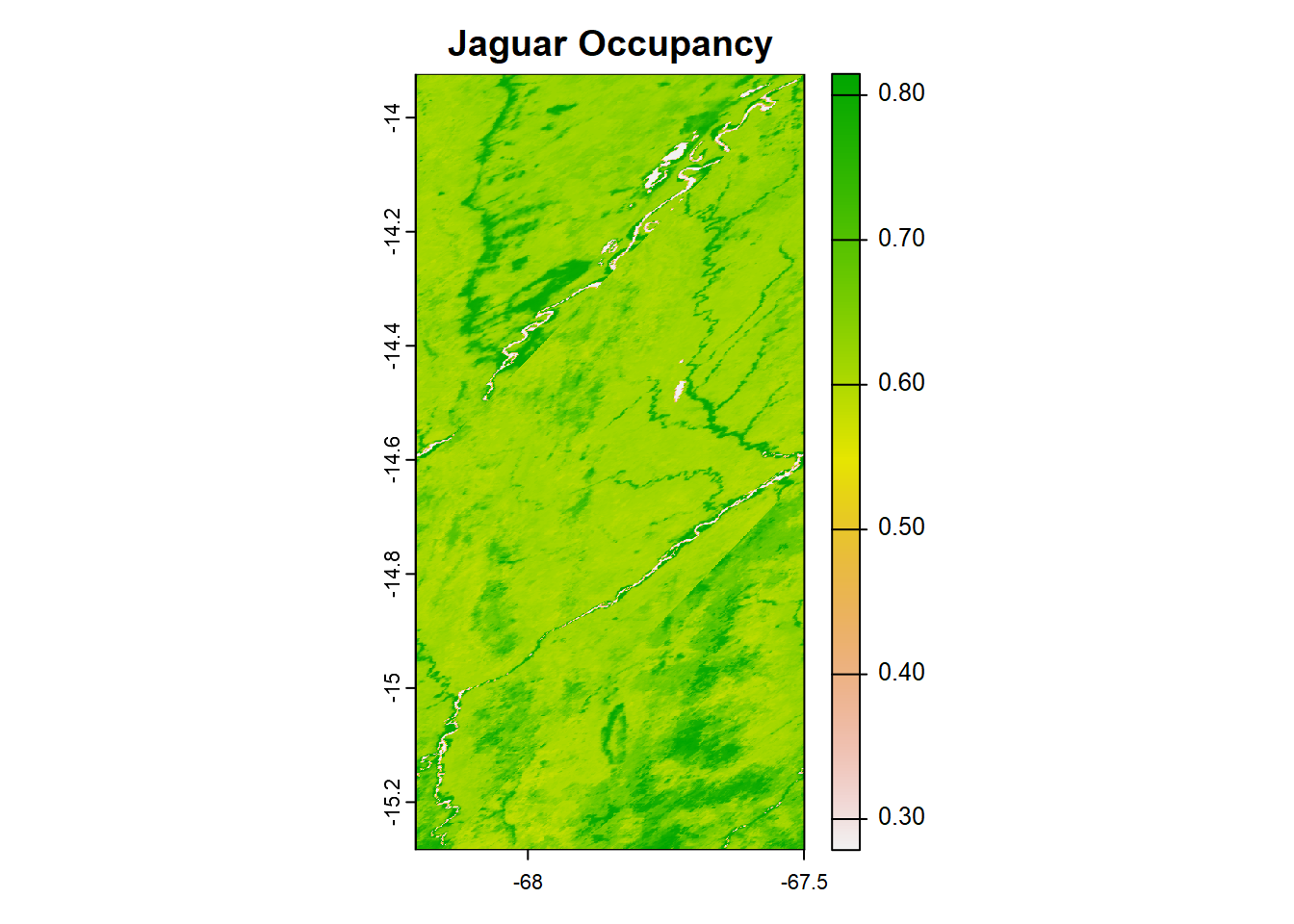
pkgs <- cite_packages(output = "paragraph", pkgs="Session", out.dir = ".")
# knitr::kable(pkgs)
pkgsWe used R version 4.3.2 (R Core Team 2023) and the following R packages: DT v. 0.32 (Xie, Cheng, and Tan 2024), elevatr v. 0.99.0 (Hollister et al. 2023), maps v. 3.4.2 (Richard A. Becker, Ray Brownrigg. Enhancements by Thomas P Minka, and Deckmyn. 2023), mapview v. 2.11.2 (Appelhans et al. 2023), sf v. 1.0.15 (Pebesma 2018; Pebesma and Bivand 2023), terra v. 1.7.71 (Hijmans 2024), tidyverse v. 2.0.0 (Wickham et al. 2019), tmap v. 3.99.9000 (Tennekes 2018), ubms v. 1.2.6 (Kellner et al. 2021), unmarked v. 1.4.1 (Fiske and Chandler 2011; Kellner et al. 2023).
print(sessionInfo(), locale = FALSE)
#> R version 4.3.2 (2023-10-31 ucrt)
#> Platform: x86_64-w64-mingw32/x64 (64-bit)
#> Running under: Windows 10 x64 (build 19042)
#>
#> Matrix products: default
#>
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] hms_1.1.3 lubridate_1.9.3 forcats_1.0.0 stringr_1.5.1
#> [5] dplyr_1.1.4 purrr_1.0.2 readr_2.1.5 tidyr_1.3.1
#> [9] tibble_3.2.1 ggplot2_3.5.1 tidyverse_2.0.0 ubms_1.2.6
#> [13] unmarked_1.4.1 elevatr_0.99.0 terra_1.7-71 tmap_3.99.9000
#> [17] maps_3.4.2 mapview_2.11.2 sf_1.0-15 DT_0.32
#> [21] grateful_0.2.4 readxl_1.4.3
#>
#> loaded via a namespace (and not attached):
#> [1] DBI_1.2.2 pbapply_1.7-2 leafpop_0.1.0
#> [4] gridExtra_2.3 tmaptools_3.1-1 s2_1.1.6
#> [7] inline_0.3.19 rlang_1.1.3 magrittr_2.0.3
#> [10] matrixStats_1.2.0 e1071_1.7-14 compiler_4.3.2
#> [13] loo_2.7.0 systemfonts_1.0.5 png_0.1-8
#> [16] vctrs_0.6.5 wk_0.9.1 pkgconfig_2.0.3
#> [19] fastmap_1.1.1 ellipsis_0.3.2 lwgeom_0.2-13
#> [22] leafem_0.2.3 utf8_1.2.4 rmarkdown_2.27
#> [25] tzdb_0.4.0 xfun_0.44 satellite_1.0.5
#> [28] jsonlite_1.8.8 uuid_1.2-0 parallel_4.3.2
#> [31] R6_2.5.1 stringi_1.8.3 RColorBrewer_1.1-3
#> [34] StanHeaders_2.32.5 jquerylib_0.1.4 cellranger_1.1.0
#> [37] stars_0.6-4 Rcpp_1.0.12 rstan_2.32.6
#> [40] knitr_1.46 base64enc_0.1-3 leaflet.providers_2.0.0
#> [43] timechange_0.3.0 Matrix_1.6-1.1 tidyselect_1.2.1
#> [46] rstudioapi_0.16.0 dichromat_2.0-0.1 abind_1.4-5
#> [49] yaml_2.3.8 codetools_0.2-19 curl_5.2.0
#> [52] pkgbuild_1.4.4 lattice_0.22-5 leafsync_0.1.0
#> [55] withr_3.0.0 evaluate_0.23 units_0.8-5
#> [58] proxy_0.4-27 RcppParallel_5.1.7 pillar_1.9.0
#> [61] KernSmooth_2.23-22 stats4_4.3.2 generics_0.1.3
#> [64] sp_2.1-3 rstantools_2.4.0 munsell_0.5.0
#> [67] scales_1.3.0 class_7.3-22 glue_1.7.0
#> [70] tools_4.3.2 leaflegend_1.2.0 data.table_1.15.0
#> [73] RSpectra_0.16-1 XML_3.99-0.16.1 grid_4.3.2
#> [76] QuickJSR_1.1.3 crosstalk_1.2.1 colorspace_2.1-0
#> [79] cols4all_0.7 raster_3.6-26 brew_1.0-10
#> [82] cli_3.6.2 fansi_1.0.6 viridisLite_0.4.2
#> [85] svglite_2.1.3 V8_4.4.2 gtable_0.3.4
#> [88] digest_0.6.34 widgetframe_0.3.1 progressr_0.14.0
#> [91] classInt_0.4-10 farver_2.1.1 htmlwidgets_1.6.4
#> [94] htmltools_0.5.7 lifecycle_1.0.4 leaflet_2.2.1
#> [97] MASS_7.3-60@online{lizcano,
author = {Lizcano, Diego},
title = {Occupancy},
date = {},
url = {https://dlizcano.github.io/WCS-CameraTrap/occupancy.html},
langid = {en}
}