Code
library(mapview)
library(sf)
library(readr) # read csv
library(DT) # tablas en html
library(unmarked)
library(terra)
library(elevatr)Modelo de ocupación espacialmente explicito. Practica con datos reales
Diego Lizcano 
Elevation as an occupancy determinant of the little red brocket deer (Mazama rufina) in the Central Andes of Colombia. Caldasia, 43(2), 392-395. https://doi.org/10.15446/caldasia.v43n2.85449
Instalamos 28 cámaras trampa entre marzo y junio de 2017 en la localidad de Quindío, donde permanecieron activas durante 35 días. En Risaralda, instalamos 60 cámaras en dos conjuntos entre marzo y julio de 2017. Estas últimas permanecieron activas durante 45 días. Instalamos todas las cámaras trampa a una distancia mínima de 500 m entre sí, en una cuadrícula regular.
Acá evaluamos la influencia de variables del terreno sobre la ocupación del venado soche (Mazama rufina) en los Andes centrales de Colombia. La ocupación aumentó con la elevación hasta los 3000 m y por encima de este valor decrece. Esta información es crucial para predecir los posibles efectos del cambio climático sobre M. rufina y otras especies de montaña.
Comenzamos cargando tres paquetes básicos necesarios para generar mapas; mapview, sf, luego cargamos readr para leer los datos y unmarked para los modelos de ocupación.
library(mapview)
library(sf)
library(readr) # read csv
library(DT) # tablas en html
library(unmarked)
library(terra)
library(elevatr)El paquete sf se utiliza para trabajar con datos espaciales y ofrece funciones para leer, escribir y analizar datos espaciales (features en inglés) de una manera sencilla y eficiente. Mapview nos permite visualizar mapas rapidamente en R.
library(maps)# read photo data in object y_full. Columns are days and rows sites
# load("data/y_full.RData") # if you got the repo in hard disk
ydata <- "https://github.com/dlizcano/Mazama_rufina/blob/main/data/y_full.RData?raw=true"
load(url(ydata))
# read camera location
# cams_loc_QR <- read.csv("data/cams_location.csv") # if you got the repo in hard disk
camdata <- "https://raw.githubusercontent.com/dlizcano/Mazama_rufina/main/data/cams_location.csv"
cams_loc_QR <- read_csv(url(camdata))En las columnas de y_full tenemos los dias de muestreo y en las filas cada uno de los sitios donde se instaló una camara trampa.
View(y_full)En la tabla cams_loc_QR tenemos las coordenadas de cada camara.
View(cams_loc_QR)Ahora vamos a usar las coordenadas de cada camara para obtener la elevación, la pendiente y el aspecto, descargando un mapa de la elevacion con el paquete elevatr y la función get_elev_raster, la cual se conecta a la nube de Amazon Web Services (AWS) y para descargar el mapa.
# convert to sf
cams_loc_QR_sf <- st_as_sf(cams_loc_QR, coords = c("Longitud", "Latitud"), crs = "+proj=longlat +datum=WGS84 +no_defs")
# convert to UTM
cams_loc_QR_sf_utm <- st_transform(cams_loc_QR_sf, "EPSG:32618")
# not required
# centroid <- c(mean(cams_loc_QR$Longitud), mean(cams_loc_QR$Latitud))
clip_window <- ext(-75.60 , -75.39, 4.59, 4.81) # extent
# bb <- c(-75.60, 4.59, -75.39, 4.81)
clip_window_utm <- terra::project(clip_window,
from=crs(cams_loc_QR_sf),
to="EPSG:32618")
# get spatial data as spatrast
srtm <- rast(get_elev_raster(cams_loc_QR_sf_utm, z=8))
# crop the raster using the vector extent
srtm_crop <- terra::crop(srtm, clip_window_utm)
# elevation.crop and terrain covs
elevation <- srtm_crop
slope<-terrain(srtm_crop, "slope", unit='degrees', neighbors=8)
aspect<-terrain(srtm_crop, "aspect", unit='degrees', neighbors=8)
roughness <- terrain(srtm_crop, "TPI", neighbors=8) #TPI (Topographic Position Index)
cov.list<-list(elevation, slope, aspect, roughness)
cov.stack<-rast(cov.list)
names(cov.stack) <- c("elevation", "slope", "aspect", "roughness" )
plot(cov.stack)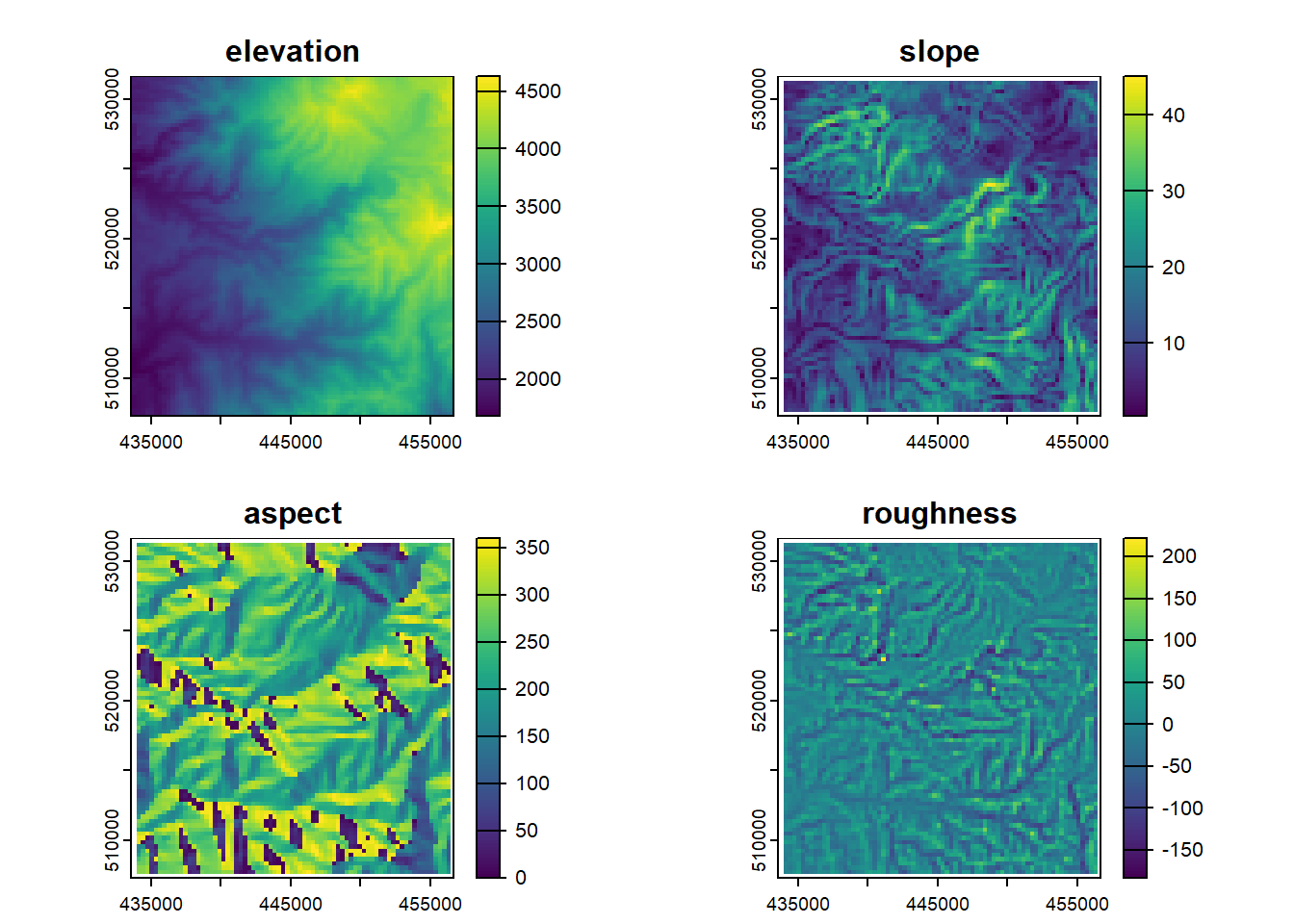
# extract covariates
cam_covs <- terra::extract (cov.stack, cams_loc_QR_sf_utm)
full_covs <- as.data.frame(cam_covs) # convert to Data frame
full_covs_1 <- scale(full_covs) #scale
full_covs_s <- as.data.frame(full_covs_1)
full_covs_s$camara <- cams_loc_QR$camara # add camera name
datatable(full_covs_s) #scaledCreamos un cobjeto que elaza los datos y las covariables para el paquete unmarked.
#############
# Occu analisys
# Make unmarked frame
umf_y_full<- unmarkedFrameOccu(y= y_full[,1:108])
siteCovs(umf_y_full) <- full_covs_s # data.frame(Elev=full_covs$Elev) # Full
#######Graficar umf
plot(umf_y_full)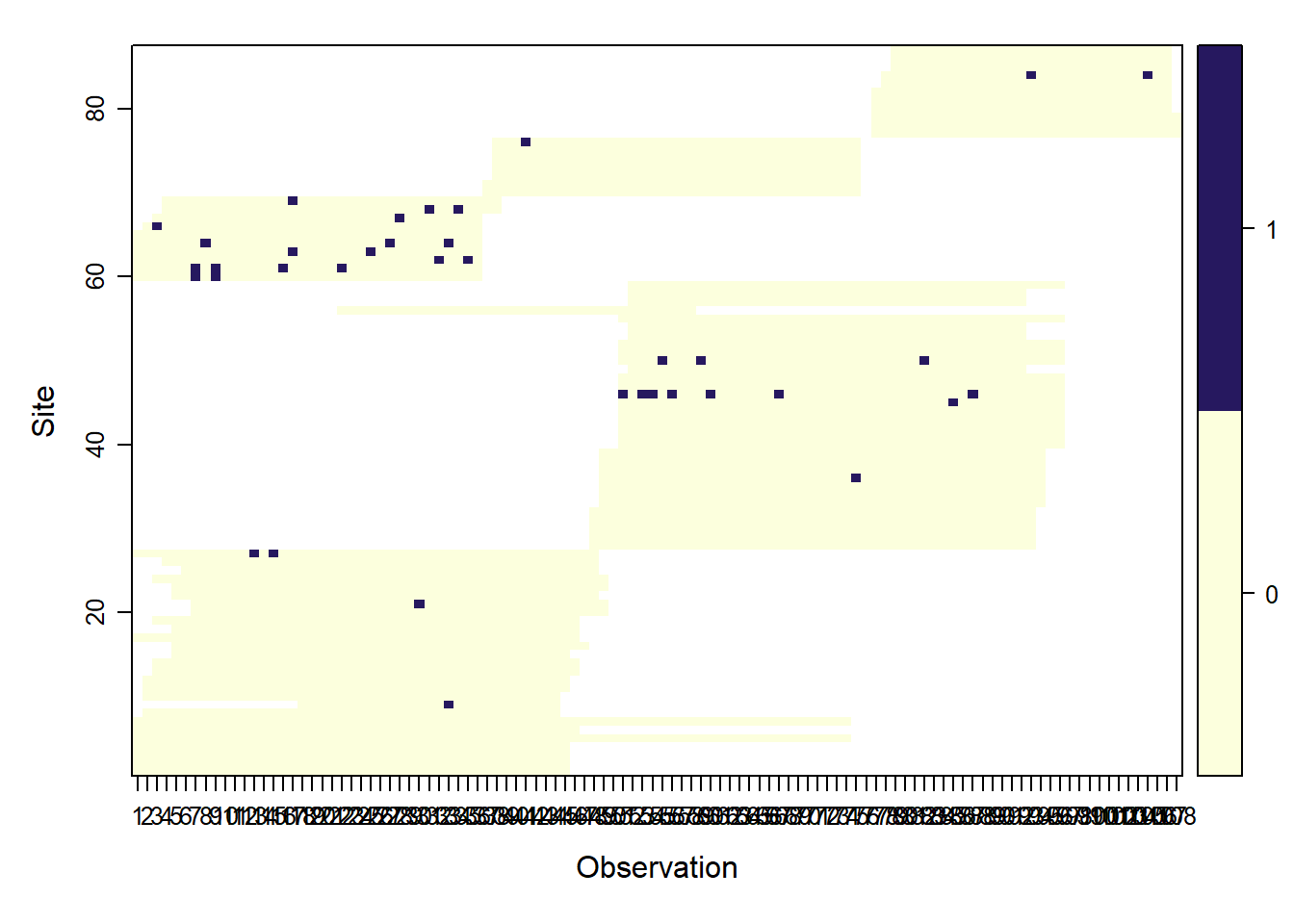
# build models
mf0<-occu(~1 ~ 1, umf_y_full)
mf1<-occu(~1 ~ elevation, umf_y_full)
mf2<-occu(~1 ~ elevation +I(elevation^2), umf_y_full)
mf3<-occu(~1 ~ slope, umf_y_full)
mf4<-occu(~1 ~ aspect, umf_y_full)
mf5<-occu(~1 ~ roughness, umf_y_full)#, starts = c(0.6, -3, 0))
mf6<-occu(~elevation +I(elevation^2) ~ elevation +I(elevation^2), umf_y_full)
mf7<-occu(~roughness ~ elevation +I(elevation^2), umf_y_full)
mf8<-occu(~slope ~ elevation +I(elevation^2), umf_y_full)
# fit list
fms1<-fitList("p(.) Ocu(.)"=mf0,
"p(.) Ocu(elev)"=mf1,
"p(.) Ocu(elev^2)"=mf2,
"p(.) Ocu(slope)"=mf3,
"p(.) Ocu(aspect)"=mf4,
"p(.) Ocu(roughness)"=mf5,
"p(elev^2) Ocu(elev^2)"=mf6,
"p(roughness) Ocu(elev^2)"=mf7,
"p(slope) Ocu(elev^2)"=mf8
)
modSel(fms1) nPars AIC delta AICwt cumltvWt
p(slope) Ocu(elev^2) 5 363.67 0.00 7.5e-01 0.75
p(.) Ocu(elev^2) 4 367.26 3.59 1.2e-01 0.87
p(roughness) Ocu(elev^2) 5 368.88 5.21 5.5e-02 0.93
p(.) Ocu(elev) 3 369.05 5.38 5.1e-02 0.98
p(elev^2) Ocu(elev^2) 6 371.23 7.57 1.7e-02 1.00
p(.) Ocu(aspect) 3 376.46 12.79 1.3e-03 1.00
p(.) Ocu(roughness) 3 377.90 14.23 6.1e-04 1.00
p(.) Ocu(slope) 3 404.43 40.77 1.1e-09 1.00
p(.) Ocu(.) 2 417.05 53.38 1.9e-12 1.00pb_f <- parboot(mf8, nsim=500, report=10) Primero creamos un set de dados nuevos con el rango de todas las covariables y luego lo usamos para predecir.
#
newdat_range<-data.frame(elevation=seq(min(full_covs_s$elevation),
max(full_covs_s$elevation),length=100),
slope=seq(min(full_covs_s$slope),
max(full_covs_s$slope), length=100),
roughness=seq(min(full_covs_s$roughness),
max(full_covs_s$roughness), length=100))
pred_det <-predict(mf8, type="det", newdata=newdat_range, appendData=TRUE)
## plot Detection en escala original
pred_det <-predict(mf8, type="det", newdata=newdat_range, appendData=TRUE)
plot(Predicted~roughness, pred_det,type="l",col="blue",
xlab="slope",
ylab="Detection Probability",
xaxt="n")
xticks <- c(-1, -0.5, 0, 0.5, 1, 1.5, 2, 2.5, 3) # -1:2
xlabs <- xticks*sd(full_covs$roughness) + mean(full_covs$roughness) #Use the mean and sd of original value to change label name
axis(1, at=xticks, labels=round(xlabs, 1))
lines(lower~roughness, pred_det,type="l",col=gray(0.5))
lines(upper~roughness, pred_det,type="l",col=gray(0.5))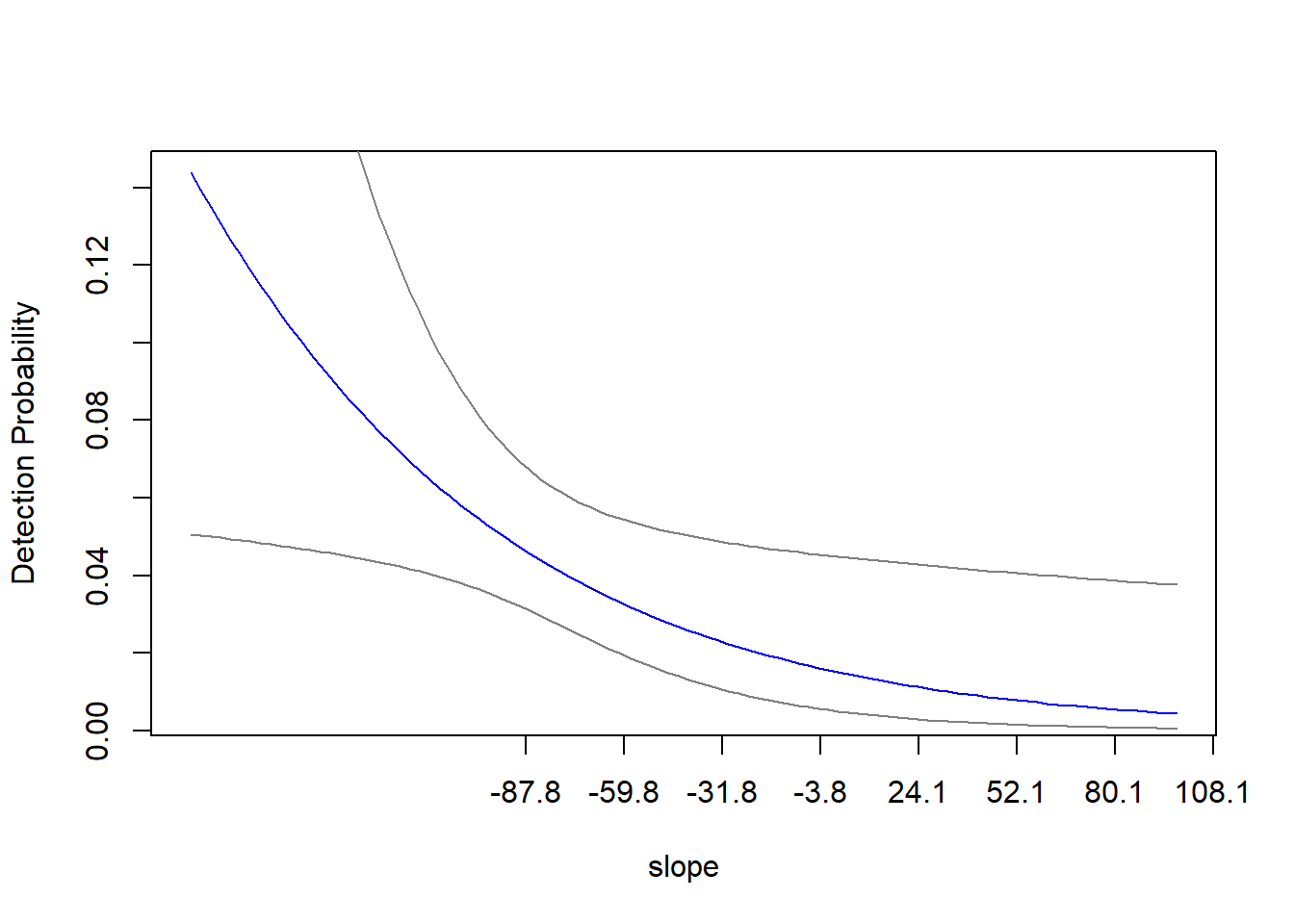
pred_psi <-predict(mf8, type="state", newdata=newdat_range, appendData=TRUE)
### Plot occupancy en escala original
plot(Predicted ~ elevation, pred_psi, type="l", ylim=c(0,1), col="blue",
xlab="Elevation",
ylab="Occupancy Probability",
xaxt="n")
xticks <- c(-1, -0.5, 0, 0.5, 1, 1.5, 2) # -1:2
xlabs <- xticks*sd(full_covs$elevation) + mean(full_covs$elevation) #Use the mean and sd of original value to change label name
axis(1, at=xticks, labels=round(xlabs, 1))
lines(lower ~ elevation, pred_psi, type="l", col=gray(0.5))
lines(upper ~ elevation, pred_psi, type="l", col=gray(0.5))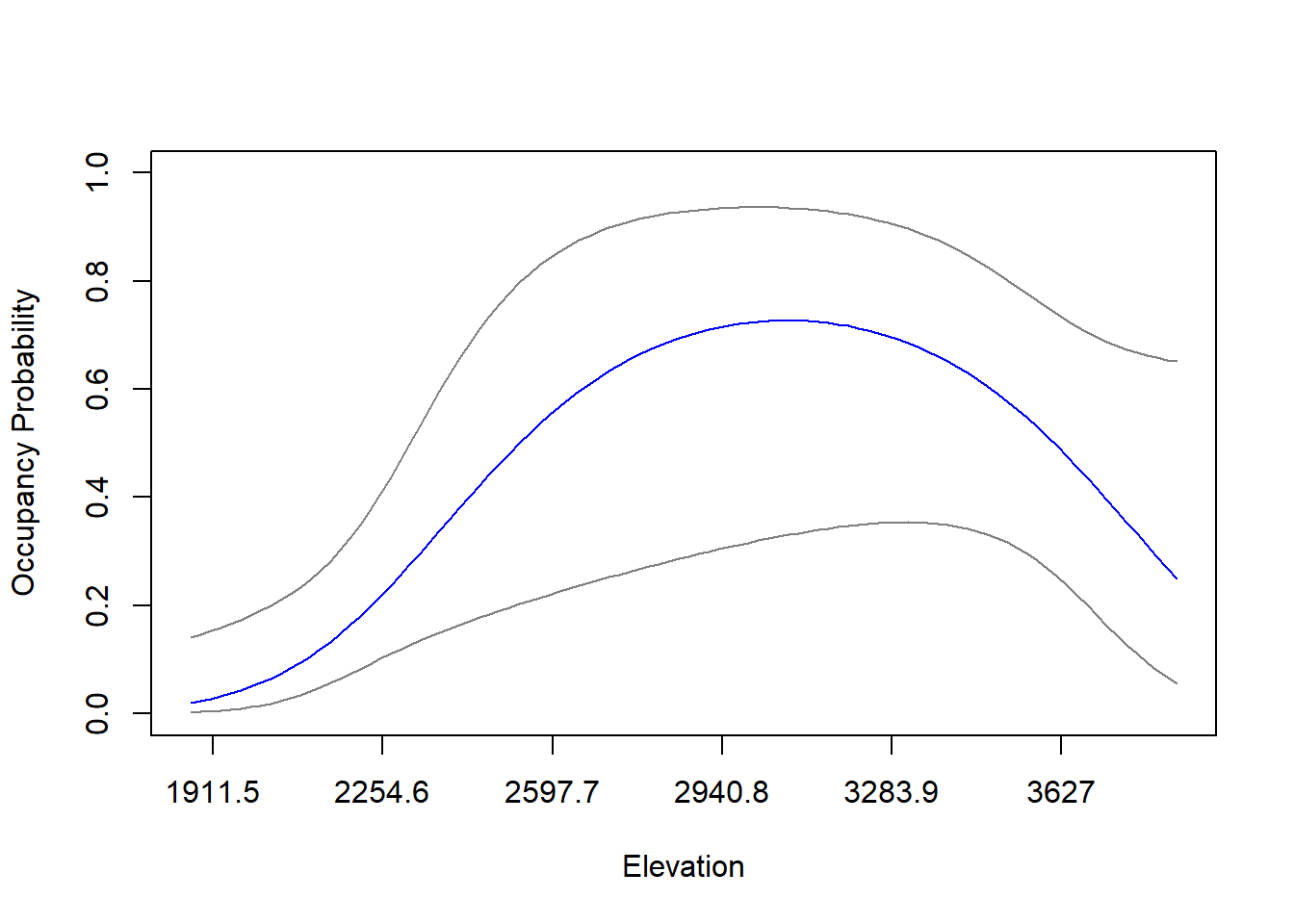
Acá usamos el raster para prededir con el mejor modelo.
# new raster data set
srtm_crop_s <- rast(list(scale(elevation),
scale(slope),
scale(roughness)
)) # scale altitud
names(srtm_crop_s) <- c("elevation", "slope", "roughness") # put names
# crs(srtm_crop_s) <- "+proj=longlat +datum=WGS84 +ellps=WGS84 +towgs84=0,0,0"
# spatial predictions
pred_p_s <-predict(mf8, type="det", newdata=srtm_crop_s)
pred_psi_s <-predict(mf8, type="state", newdata=srtm_crop_s) En éste caso, este paso no require la conversión.
pred_p_r <- pred_p_s # * sd(full_covs$roughness) + mean(full_covs$roughness)
pred_psi_r <- pred_psi_s # * sd(full_covs$roughness) + mean(full_covs$roughness)
# w <- project(pred_p_r, "EPSG:32618")
# clr <- colorRampPalette(brewer.pal(9, "YlGn"))mapview (pred_p_r[[1]], alpha=0.5) + mapview(cams_loc_QR_sf, cex = 1.5, color = "green")mapview (pred_psi_r[[1]], alpha=0.5) + mapview(cams_loc_QR_sf, cex = 1.5, color = "green")Esperamos que haya disfrutado de este curso.
Recuerde que la práctica es fundamental para desarrollar sus habilidades de R, por lo que le recomendamos que intente hacer de R una parte integral de sus flujos de trabajo. Afortunadamente, con la abundancia de recursos disponibles gratuitamente y la inmensa comunidad de usuarios, ¡aprender R nunca ha sido tan fácil!
Escribir código consiste en ensayo error y un 90% buscar la respuesta en Google.
Si busca un problema en la web, como “ggplot remove legend”, normalmente obtendrá una respuesta bastante decente en Stack Overflow o en un sitio similar.
Si la respuesta aún no existe en línea, regístrese en Stack Overflow y pregúntela usted mismo (pero primer dedique tiempo suficiente en buscar … ¡nadie quiere ser etiquetado por duplicar una pregunta existente!).
Otra buena idea es buscar un grupo de apoyo local. El uso de R es una experiencia emocional, la curva de aprendizaje al comienzo es bien empinada, la frustración es común, pero luego de un tiempo la alegría de encontrar una solución puede ayudarnos a persistir. Tener a otras personas para ayudar, o simplemente escuchar sus frustraciones es una gran motivación para seguir aprendiendo R.

pkgs <- cite_packages(output = "paragraph", pkgs="Session", out.dir = ".")
# knitr::kable(pkgs)
pkgsWe used R version 4.4.2 (R Core Team 2024) and the following R packages: DT v. 0.33 (Xie, Cheng, and Tan 2024), elevatr v. 0.99.0 (Hollister et al. 2023), maps v. 3.4.2.1 (Richard A. Becker, Ray Brownrigg. Enhancements by Thomas P Minka, and Deckmyn. 2024), mapview v. 2.11.2 (Appelhans et al. 2023), sf v. 1.0.19 (Pebesma 2018; Pebesma and Bivand 2023), terra v. 1.8.21 (Hijmans 2025), tidyverse v. 2.0.0 (Wickham et al. 2019), unmarked v. 1.4.3 (Fiske and Chandler 2011; Kellner et al. 2023).
print(sessionInfo(), locale = FALSE)R version 4.4.2 (2024-10-31 ucrt)
Platform: x86_64-w64-mingw32/x64
Running under: Windows 10 x64 (build 19045)
Matrix products: default
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] maps_3.4.2.1 elevatr_0.99.0 terra_1.8-21 unmarked_1.4.3
[5] DT_0.33 readr_2.1.5 sf_1.0-19 mapview_2.11.2
[9] grateful_0.2.10
loaded via a namespace (and not attached):
[1] tidyselect_1.2.1 farver_2.1.2 fastmap_1.2.0
[4] leaflet_2.2.2 digest_0.6.37 lifecycle_1.0.4
[7] magrittr_2.0.3 compiler_4.4.2 rlang_1.1.4
[10] sass_0.4.9 progress_1.2.3 tools_4.4.2
[13] leafpop_0.1.0 yaml_2.3.10 knitr_1.49
[16] brew_1.0-10 prettyunits_1.2.0 htmlwidgets_1.6.4
[19] bit_4.5.0.1 sp_2.1-4 classInt_0.4-10
[22] curl_6.0.0 RColorBrewer_1.1-3 abind_1.4-8
[25] KernSmooth_2.23-24 purrr_1.0.2 grid_4.4.2
[28] stats4_4.4.2 e1071_1.7-16 leafem_0.2.3
[31] colorspace_2.1-1 progressr_0.15.0 scales_1.3.0
[34] MASS_7.3-61 cli_3.6.3 rmarkdown_2.29
[37] crayon_1.5.3 rstudioapi_0.17.1 httr_1.4.7
[40] tzdb_0.4.0 minqa_1.2.8 DBI_1.2.3
[43] pbapply_1.7-2 cachem_1.1.0 proxy_0.4-27
[46] splines_4.4.2 stars_0.6-8 slippymath_0.3.1
[49] parallel_4.4.2 base64enc_0.1-3 vctrs_0.6.5
[52] boot_1.3-31 Matrix_1.7-1 jsonlite_1.8.9
[55] hms_1.1.3 bit64_4.5.2 systemfonts_1.1.0
[58] crosstalk_1.2.1 jquerylib_0.1.4 units_0.8-5
[61] glue_1.8.0 nloptr_2.1.1 codetools_0.2-20
[64] leaflet.providers_2.0.0 raster_3.6-30 lme4_1.1-35.5
[67] munsell_0.5.1 tibble_3.2.1 pillar_1.10.1
[70] htmltools_0.5.8.1 satellite_1.0.5 R6_2.6.1
[73] vroom_1.6.5 evaluate_1.0.1 lattice_0.22-6
[76] png_0.1-8 bslib_0.8.0 class_7.3-22
[79] uuid_1.2-1 Rcpp_1.0.13-1 svglite_2.1.3
[82] nlme_3.1-166 xfun_0.49 pkgconfig_2.0.3 @online{lizcano2025,
author = {Lizcano, Diego},
title = {Modelado de La {Ocupación,} Abundancia y Densidad de
Poblaciones: Enfoque Frecuentista y Bayesiano En {R.} {Modelo} de
Ocupación de Multiples Temporadas},
date = {2025-06-24},
url = {https://dlizcano.github.io/occu_multi_season/},
langid = {en}
}